マシンラーニング-ランダムForestクリーンアップ、メンバーシップの決定、モデルの作成
ランダムForestとは?
決定樹の森.
特徴としてRandomを選択し,Nodeを指定し,四半期ごとにDecision TreeのようにGenieの不一致性を理解し,複数のWeaker学習者を作成して比較し,その中で最適予測を行うモデルを作成した.

画像ソース:https://www.youtube.com/watch?v=J4Wdy0Wc_xQ
Random Forestメンバー
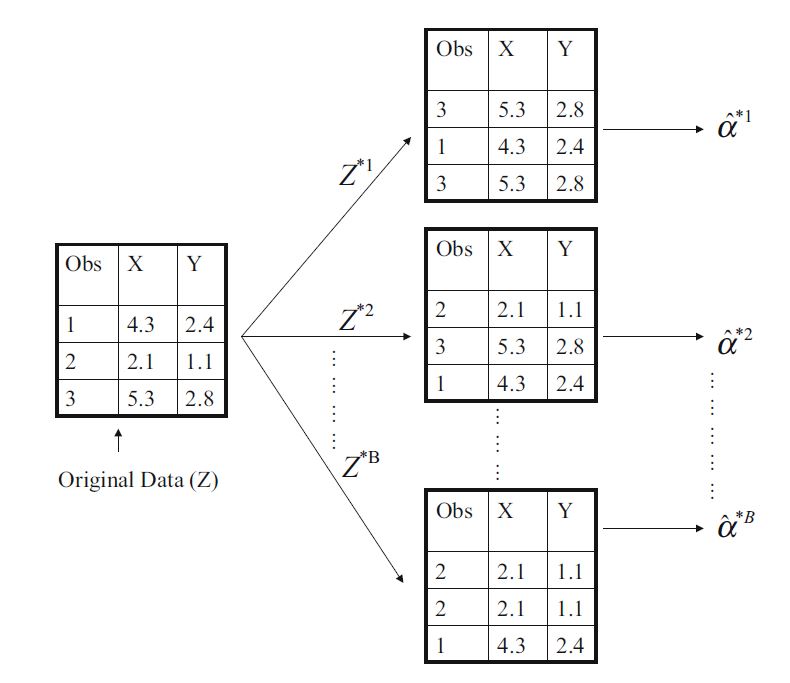
1.ガイドバーサンプリング(Bootstrap):
これはRandomForest(フォレスト)を作成するために使用される各Weaker学習者を作成するために使用されるサンプリング方法であり,特徴をランダムに抽出し,特徴内でもサンプルをランダムに抽出(繰り返し可能にするため)して抽出する方法である.
データセットにn個のsampleがある場合、既存のデータセットと同様に、n個のsampleを抽出することを元に戻してNew Bootstrapデータセットを作成し、それを複数回繰り返しサンプリングする方法.

画像ソース:https://blog.kakaocdn.net/dn/WnWjt/btqMvfwFqg1/8AwRUJYDc6nJHws5RqJsg1/img.jpg
{kind=link}
2.ブランチ(エッジ、ブランチ)と任意の特性選択(ランダム選択):
RandomForestのもう一つの特徴は、四半期に次の特性を選択する際にもランダムな方法を採用することです.
言い換えれば、Baggingのこの特徴は、Bootstrapサンプリングのデータセットでランダムに特徴を選択して複数のTree分類器を作成することであり、Ensemble技術、並列構造と言える.これはまた、予防と適切な利点であるDecision Treeの大きな欠点と見なすことができる.
3.OOB検証:

Bootstrapは、1つのデータセットのリカバリによって複数の新しいデータセットを抽出し、それ自体をある程度検証します.Original Datasetのようにn個のサンプルで復元抽出を行うと,抽出されないサンプルも発生する.このように選択されていないサンプルをOOB(Out of Bag Data)と呼び、それらを検証セット(Validation set)として自己検証する.
pythonのOOBスコアを表示する例は、次のモデリングで一緒に表示されます.
ランダムForestモデルの作成
import pandas as pd
# iris dataset 불러오기
df = sns.load_dataset('iris')
df
前回Treeモデルを使用して作成したDecision Treeのパフォーマンスと比較するために、「iris」データセットもロードします.
# target 선정
target = 'species'
df['species']= [1 if i == 'versicolor' else 0 for i in df['species']]
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size = 0.2, random_state = 2)
feature = df.drop(columns = target).columns
X_train = train[feature]
y_train = train[target]
X_test = test[feature]
y_test = test[target]
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, roc_auc_score, confusion_matrix
# RandomForest 앙상블 모델 작성
rf = RandomForestClassifier( oob_score= True)
rf.fit(X_train, y_train)
# test 셋에 모델 적용
y_pred = rf.predict(X_test)
y_pred_proba = rf.predict_proba(X_test)[:,1]
# test 셋 적용 결과
print('\n[test] accuracy:',rf.score(X_test, y_test))
print('[test] f1:', f1_score(y_test, y_pred))
print('[test] auc:', roc_auc_score(y_test, y_pred_proba))
print('\n oob_score:',rf.oob_score_)[output]
[test] accuracy: 0.9666666666666667
[test] f1: 0.9333333333333333
[test] auc: 0.9460227272727273
oob_score: 0.9416666666666667
これは、Decision Treeモデルを作成したときに、モデルを除いてまったく同じモデルが作成されたときの結果です.すべての同じ条件でモデリングを行ったとしても,Decision Treeよりも性能が優れていることが分かる.
Random Forestのパラメータでoobscore=Trueを設定すると、以降になります.自己検証結果はoob scoreで表示できます.
Reference
この問題について(マシンラーニング-ランダムForestクリーンアップ、メンバーシップの決定、モデルの作成), 我々は、より多くの情報をここで見つけました https://velog.io/@dlskawns/Machine-Learning-Random-Forest-정리-구성원리-파악-및-모델-작성テキストは自由に共有またはコピーできます。ただし、このドキュメントのURLは参考URLとして残しておいてください。
Collection and Share based on the CC Protocol