機械学習で必殺技分類(動作分類モデル作成からiOSでの推論実行まで:失敗編)
動画を機械学習して、動作の種類を判定する
GUIで機械学習ができるCreateML(Macで実行可能)。
動作の分類(Action Clasification)もできます。
実は僕は今回学習に失敗したのですが、作業フローはひととおり書いたので、公開しちゃいます。
【こういうのが作りたかった】

手順(データセット準備)
1、動画を集める。
分類したい動作の動画を集めます。
今回はこのようなアクションを用意してみました。



ピースサインなど静止的な動きだと画像分類で十分なので、動画シーケンスに意味のある動きにしました。
集める動画の推奨事項
・一つのアクションに50個以上の動画を集める
・アプリで使うフレームレート以上の動画を集める(トレーニング時に解析する動画のフレームレートを指定する必要がある。アプリで実行する際も、このフレームレートがを基準に解析する)
・カメラは固定
・うつすのは一人
・全身を映す
・明るい環境で
・ぶかぶかすぎる服は適さない
・背景に溶け込みすぎている服の色も適さない
・アプリでいろんな角度からキャプチャする場合は、データセットもいろんな角度のものを用意する
・一つの動画に、一つのアクションの複数回の動作が入っている場合、動作の間の静止や間隔は最小限に抑える。
・静止が入る場合は、その部分をトリミングするか、注釈つきのデータセットにする。
・ネガティブケースを入れる(アプリ実行時に起こり得る他の動作。例えば、筋トレ前後でフレームに出入りする歩行シーンを入れる。)
・静止ケースを入れる(筋トレ前後で動かずに座っている状態など。)
2、データを整理する(フォルダ分け、もしくはアノテーション・ファイルをつける)
CreateMLに与えるデータをフォルダ分けしてデータセットにします。
フォルダ分けには二つの方法があります。
構成方法1、アクションごとにビデオをフォルダ分けする

「一つの動画に一つのアクション分類」になるように、きちんと動画をトリミングしている場合にこの方法が使えます。
構成方法2、注釈ファイルをつける
一つのビデオに複数のアクションが含まれる場合は、csvやjsonでアノテーションファイル(注釈ファイル)を作ります。
方法1、は一つの動画に一つの動作を隙間なく撮影するもしくはトリミング編集するなど、留意が必要です。
ビデオを細かく撮影したり、後でトリミングするのはけっこう手間なため、僕の個人的おすすめは方法2、です。
アノテーションファイルの例
jsonでは以下のようにアクションごとに「ファイル名、ラベル、時間」キーの辞書の配列を作ります。
時間の形式は、秒数の整数もしくは小数が認識されます。
[
{
"video" : "killMove1.mov",
"label" : "Nmehameha",
"start" : 0,
"end" : 3.1
},
{
"video" : "killMove1.mov",
"label" : "Nkankousappou",
"start" : 3.2,
"end" : 6
},
{
"video" : "killMove2.mov",
"label" : "Negative",
"start" : 0,
"end" : 3.7
},
{
"video" : "killMove2.mov",
"label" : "Ki",
"start" : 3.8,
"end" : 6.5.
}
]
注意:公式ドキュメントには、String形式の分:秒でも、時間:分:秒.コンマ秒でも認識されるとありますが、これはなぜか認識されません。
// これらのJson形式は認識されないので注意
[
{
"video" : "specialMoves.mov",
"label" : "Nmehameha",
"start" : "8:3.2",
"end" : "8:4.5"
},
{
"video" : "specialMoves.mov",
"label" : "Ki",
"start" : "1:59:5.8",
"end" : "1:59:7"
},
{
"video" : "specialMoves.mov",
"label" : "Nkankousappou",
"start" : "1:59:14",
"end" : "1:59:15.1"
}
]
手順(学習)
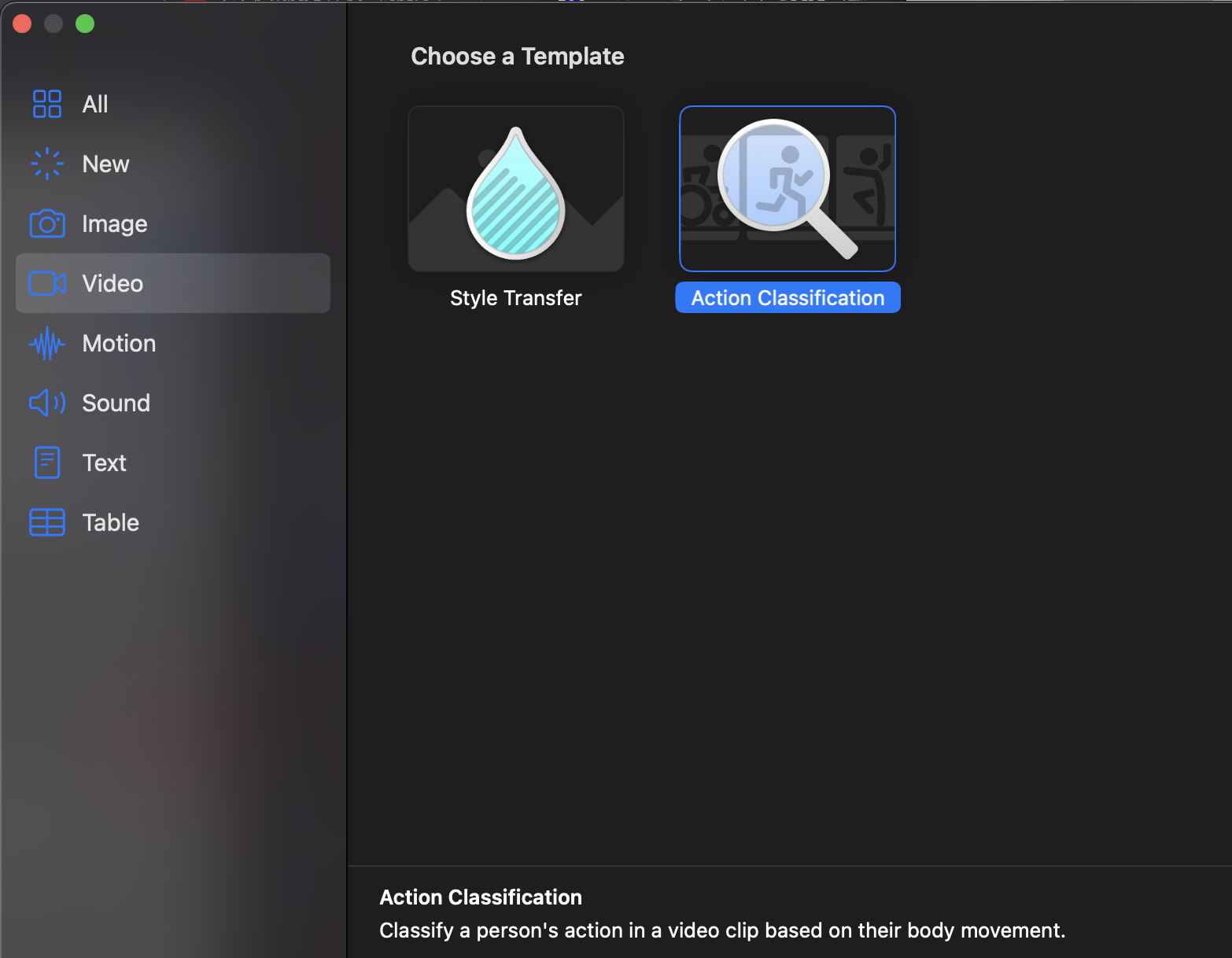
3、CreateMLでActionClassificationを開く
XcodeをControlクリックしてOpenDeveloperToolからCreateMLを開いて以下を選択。
4、学習データを指定
「Training Data」の項目から学習データのフォルダを選択します。
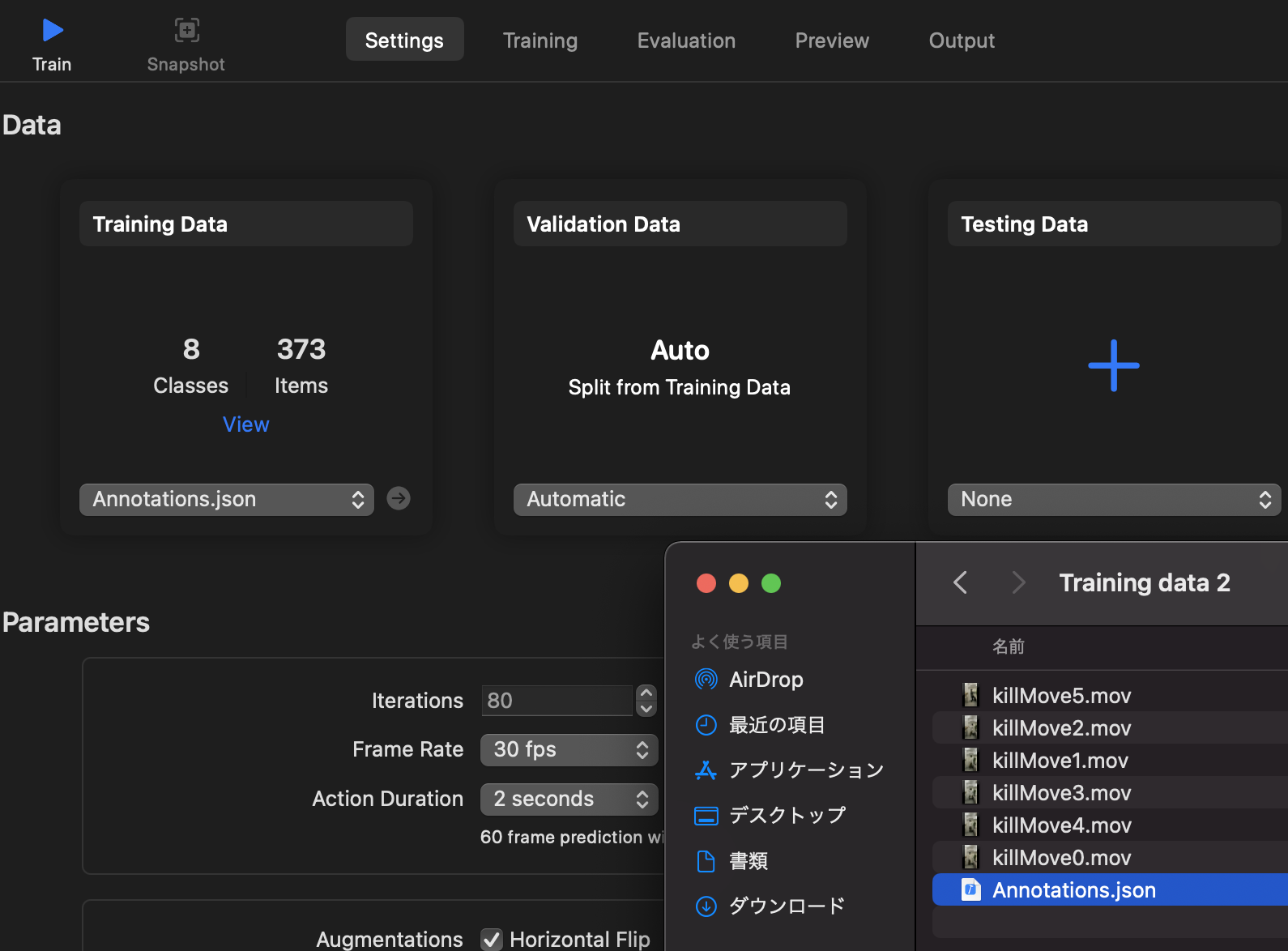
注意:JSONを読み込ませる場合は、JSONファイルを直接選択する必要があります。フォルダ選択では認識しません。
検証データは学習データと別に用意してもいいし、しなくてもOKです。指定しない場合はcreateMLがトレーニングデータの一部を検証データとしてより分けてくれます。

5、学習の設定をする
以下の設定をします。
パラメーター
Iterations
計算ステップ数。CreateMLがデータセットから自動で設定してくれます。
増やしたり減らしたりもできます。
Frame Rate
アプリで想定するフレームレート。
データセットはこの数値以上のフレームレートで用意する必要があります。
action duration:
アクション1回に想定される時間を設定します。
これによってcreateMLはアクション分析のフレーム間隔を認識できます。
Augmentations
データを水増しできます。
アクションの左右がどちらでもいい場合は、Horizontal Flip(画像を水平にひっくり返して学習データを増やす)でデータを2倍に拡張できます。
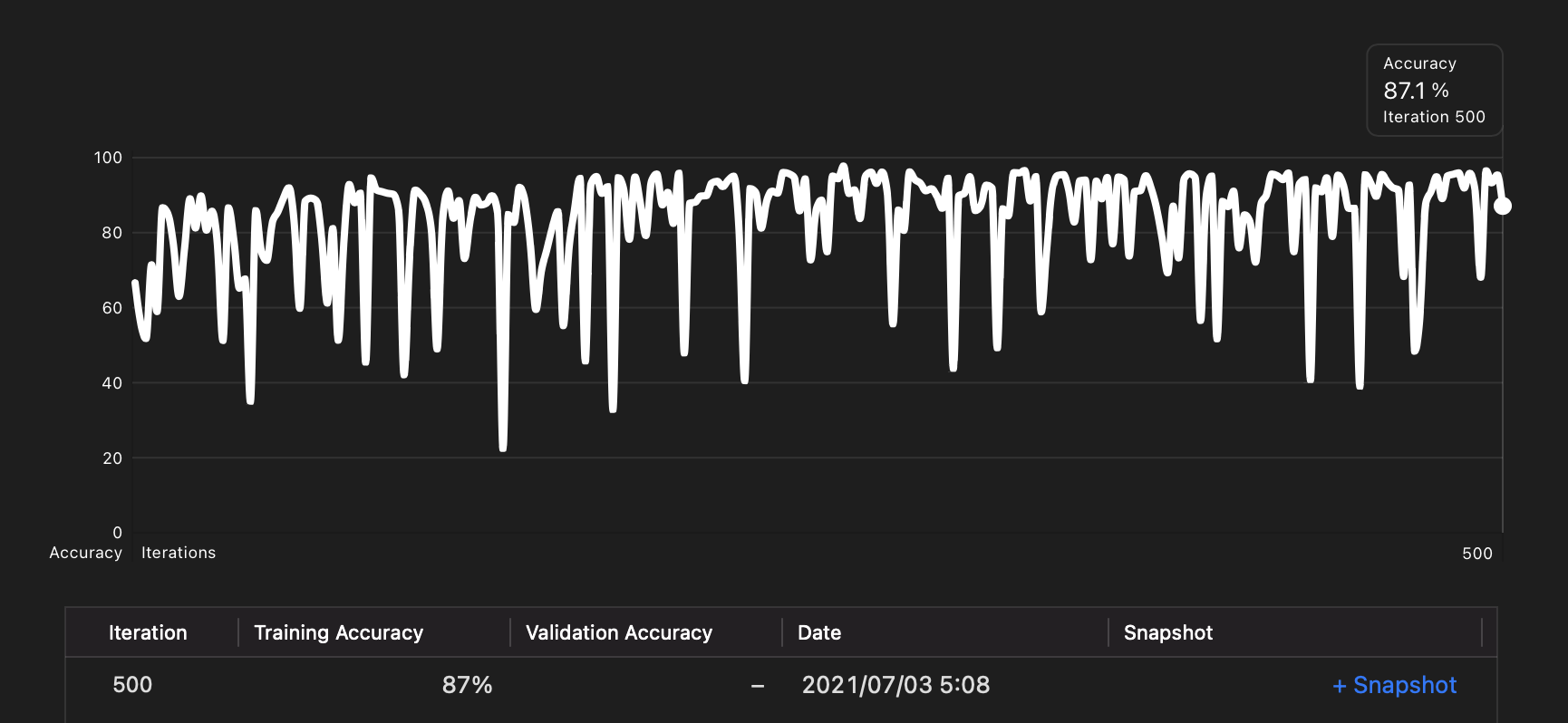
6、学習を開始する
「Run」ボタンで学習を開始します。
自動で指定した計算回数まで学習します。
手順(学習結果)
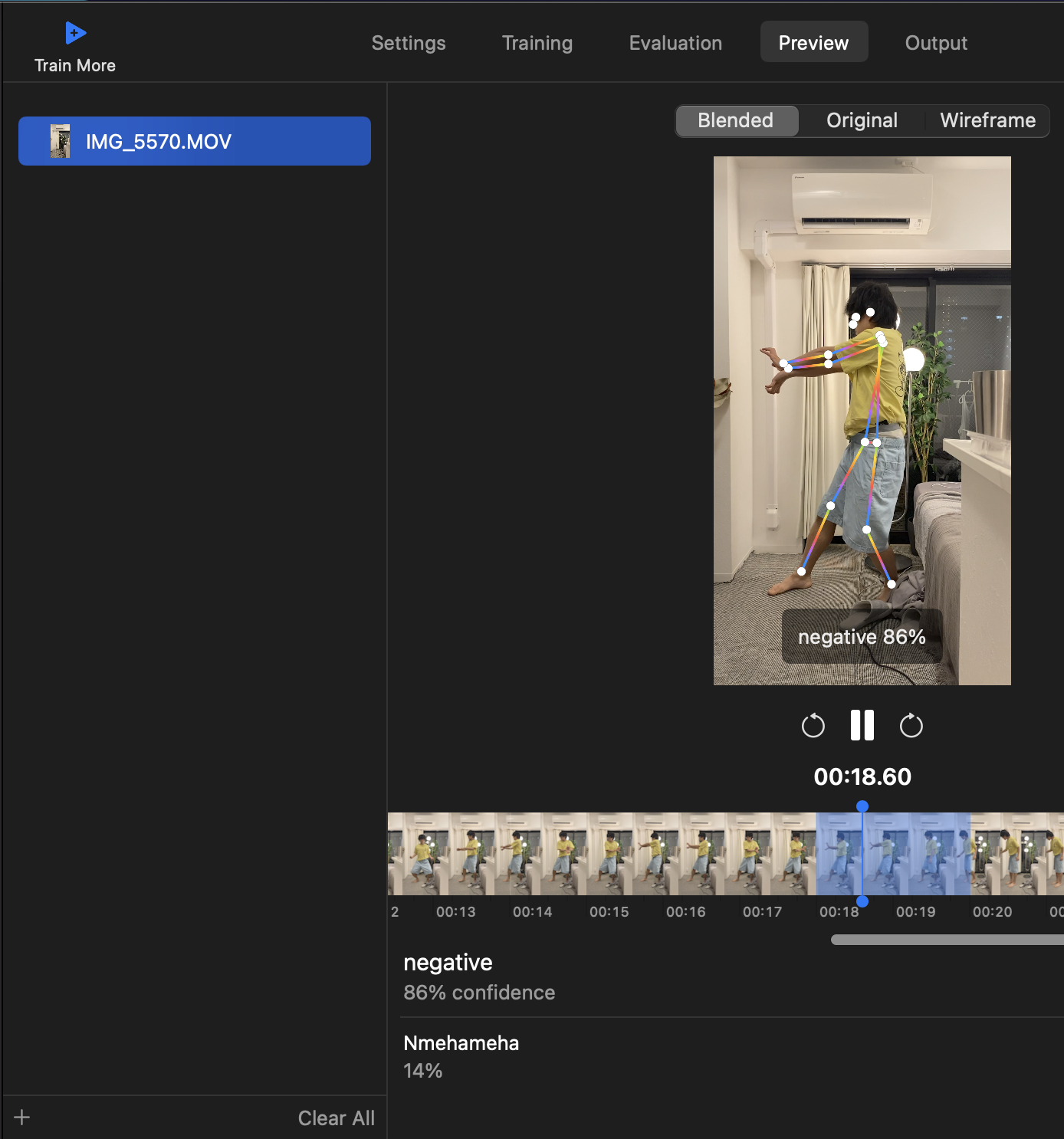
7、手持ちの動画でモデルをためしてみる
CreateMLのPreviewタブをクリックし、動画ファイルをドロップすると、作成したモデルを試せます。
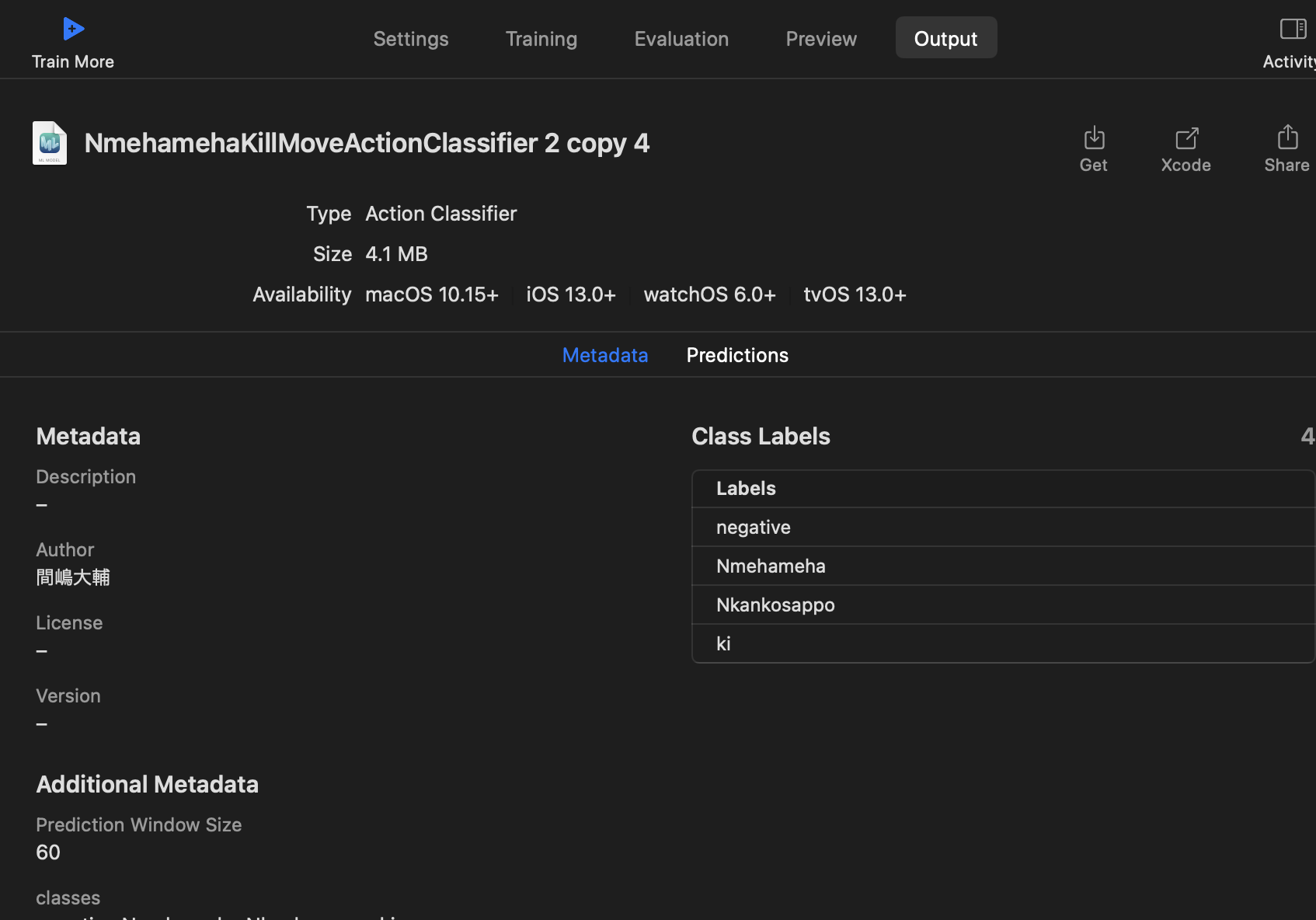
8、CoreMLモデルを取得する
CreateMLのOutputタブをクリックし、Getをクリックすると、作成したモデルのCoreMLファイルが取得できます。
手順(モバイルでの推論)
9、CoreMLファイルをアプリにバンドルする
取得したCoreMLモデルをアプリで使うには、アプリにCoreMLファイルをドロップしてバンドルします。
以下のプロセスで、Visionフレームワークを使ってカメラフィードから人体の特徴ポイントを取得し、CoreMLフレームワークでモデルを実行します。
10、人体ポーズの特徴ポイントを取得する
まずは Vision で人体ポーズの特徴ポイントを検出し、その特徴ポイントをモデルに与えます。
VisionのVNDetectHumanBodyPoseRequestで人体のキーポイントを取得します。
do {
let request = try VNDetectHumanBodyPoseRequest()
let handler = try VNImageRequestHandler(cvPixelBuffer: capturedImage)
// AVFoundationやARKitなどで、カメラフィードから取得したフレームのPixelBufferを与える
try handler.perform([request])
guard let poses = request.results as? [VNRecognizedPointsObservation] else {return}
// これが1フレーム分の人体の特徴ポイント
poseWindow.append(poses.first)
} catch let error {
print(error)
}
//※ カメラからリアルタイムでフレームを与える場合、計算コストからカメラ・プレビューをブロックすることがあるので、グローバルキューで実行しましょう。
上記は、1フレーム分の人体の特徴ポイントです。
動画解析ですので、特徴ポイントを必要フレーム分ためて、モデルにあたえます。
60 フレーム分が必要な場合は、以下のように配列にします。
private lazy var posesWindow:[VNRecognizedPointsObservation] = { // 特徴ポイントの配列を作る
var window = [VNRecognizedPointsObservation]()
window.reserveCapacity(predictionWindowSize) // 必要なフレーム分のスペースを確保
return window
}() {
didSet {
if posesWindow.count == predictionWindowSize {
// 必要なフレーム枚数がたまったら、推論を実行
do {
try makePrediction()
} catch let error {
print(error)
}
}
}
}
var predictionWindowSize: Int = 60
11、特徴ポイントをマルチアレイ(多次元配列)に変換する
必要なフレーム分の人体の特徴ポイントがたまったら、モデルのインプット用にマルチアレイにしてからモデルにあたえます。
【特徴ポイント × XY座標の信頼度 × 必要フレーム数】の3次元配列マルチアレイにします。
この変換には Vision のメソッドをつかいます。
VNRecognizedPointsObservationを【特徴ポイント × XY座標の信頼度】のマルチアレイに変換してくれるkeypointsMultiArrayメソッドです。
// func makePrediction() throws {
let poseMultiArrays: [MLMultiArray] = try posesWindow.map { person in
guard let person = person else {
return makeZeroedMultiArray() // ポーズリクエストの結果がnil(人が映っていない)場合は、[1,3,18]が全て0値のマルチアレイを入れる
}
return try person.keypointsMultiArray() // 1フレーム分の人体ポイントを、ポイントと信頼度の配列にしてくれる Vision のメソッド
}
let modelInput = MLMultiArray(concatenating: poseMultiArrays, axis: 0, dataType: .float)
// モデルに必要なフレーム量の配列にまとめる
人体が映っていない時は、全ての値が0のマルチアレイをモデルに与えます。
ゼロ・マルチアレイの作り方はこちら。
private func makeZeroedMultiArray() -> MLMultiArray {
let shape:[Int] = [1,3,18]
guard let array = try? MLMultiArray(shape: shape as [NSNumber],
dataType: .double) else {
fatalError("Creating a multiarray with \(shape) shouldn't fail.")
}
guard let pointer = try? UnsafeMutableBufferPointer<Double>(array) else {
fatalError("Unable to initialize multiarray with zeros.")
}
pointer.initialize(repeating: 0.0)
return array
}
12、インプットをモデルにあたえる(推論実行)
取得した指定フレーム分のマルチアレイをモデルに与えます。
CoreMLフレームワークを使います。
// func makePrediction() throws {
// let poseMultiArrays: [MLMultiArray] = try posesWindow.map { person in
// ............ 上記
// ............
// let modelInput = MLMultiArray(concatenating: poseMultiArrays, axis: 0, dataType: .float)
let prediction = try classifier.prediction(poses: modelInput)
posesWindow.removeAll() // 次の推論のために、ためたフレームを空にする
print(prediction.label) // 最も信頼度の高い動作のラベル
print(prediction.labelProbabilities[prediction.label]) // 信頼度
与えた動画(必要フレーム分の特徴ポイントの配列)に対しての推論結果がラベルと信頼度として返ってきます。
Nmehameha
Optional(0.728015124797821)
13、失敗談
僕が試した時は、データ数が少なかったせいか、不正解のラベルがつくことも多かったです。
リアルタイムで動作解析をして、AR効果をつけたかったのですが。
ちなみに、GifのAR効果は別の方法を用いて作成しました。ARKitのボディ・スケルトンの認識です。
ARKitで両手のポイントを取得し、「手が体の中央からどれくらい離れているか」と「両手の距離で必殺技の体勢をしているか」を判定しました。
機会があれば、CreateMLのシーケンシャルな動作解析を再チャレンジしたいところです。
🐣
フリーランスエンジニアです。
お仕事のご相談こちらまで
[email protected]
Core MLやARKitを使ったアプリを作っています。
機械学習/AR関連の情報を発信しています。
Author And Source
この問題について(機械学習で必殺技分類(動作分類モデル作成からiOSでの推論実行まで:失敗編)), 我々は、より多くの情報をここで見つけました https://qiita.com/john-rocky/items/4fae5f963824dbe65bdc著者帰属:元の著者の情報は、元のURLに含まれています。著作権は原作者に属する。
Content is automatically searched and collected through network algorithms . If there is a violation . Please contact us . We will adjust (correct author information ,or delete content ) as soon as possible .