HashMapのHash衝突解決策と将来の改善
6345 ワード
説明:ネット上の二つの文章を参考にして簡単にまとめました.http://blogread.cn/it/article/7191?f=wb ,http://it.deepinmind.com/%E6%80%A7%E8%83%BD/2014/04/24/hashmap-performanc-i-java-8.
1.HashMap位置決定と記憶
前のソースコードの分析によって、HashMapはいわゆる「Hashアルゴリズム」を採用して、各要素の記憶位置を決定します.プログラムがput(String,Obect)方法を実行すると、システムはStringを呼び出すhashCode()方法を得て、そのhashCodeの値を得る.JavaオブジェクトごとにhashCode()方法があり、この方法でhashCodeの値を得ることができる.このオブジェクトのhashCode値を取得すると、システムはこのhashCodeの値に基づいてこの要素の格納位置を決定します.ソースは以下の通りです

2.Hash衝突発生と解決
Hashmapの中のbucketにはチェーンテーブルの形式が現れています.ハッシュ表で解決する問題の一つはハッシュ値の衝突問題です.チェーン表法は同じsh値の対象をチェーンにしてhash値に対応する溝に置く方法です.オープンアドレス法は、あるスロットビットがすでに占有されている場合に、次の使用可能なスロットビットを探し続ける検出アルゴリズムによって行われる.java.util.hashMapが採用しているチェーンの方式は、チェーンは一方向チェーンです.シングルチェーンテーブルを形成するコアコードは以下の通りです.
上記の方法のコードは簡単ですが、システムは常に新しく追加されたEntryオブジェクトをtable配列のbucketIndexインデックスのところに入れます.もしbucketIndexインデックスにEntryオブジェクトが存在したら、新しく追加されたEntryオブジェクトは元のEntryオブジェクトに向けられます.つまり上のプログラムコードのe変数はnull、つまり新しく入れたEntryオブジェクトはnull、つまりEntryチェーンが発生していません. HashMapの中にhash衝突が発生していない時、シングルチェーンテーブルを形成していない時、hashmapは元素を探してとても速くて、get()方法は直接元素に位置することができます.検索したいEntryが見つかるまでは、ちょうど検索するEntryがEntryチェーンの一番端にあるなら、システムは最後まで循環しなければなりません.
以上から分かるように、複数のhashCodeの値が同じ桶に落ちた場合、これらの値はチェーンに格納されている.最悪の場合、すべてのkeyは同じ桶にマッピングされ、hashmapはチェーンに縮退します.検索時間はO(1)からO(n)までです.つまり、私たちはこのHash衝突問題をチェーンで解決します.
3.Hash衝突性能分析
Java 7:hashMapのサイズが大きくなるにつれて、get()法のオーバーヘッドも大きくなります.すべての記録は同じ桶の中の超長いチェーンテーブルの中にあるので、平均的に1つの記録を調べるには半分のリストを巡る必要があります.でも、Java 8の表現はとてもいいです.ロゴの曲線ですので、何桁もの性能が必要です.深刻なハッシュ衝突があっても、最悪の場合ですが、この同じ基準テストはJDK 8における時間の複雑さはO(logn)です.JDK 8の曲線を単独で見るとより明確になります.これは対数線形分布です.
4.Java 8衝突最適化の向上
なぜこのような性能が向上したのですか?ここでは大きなO記号が使われていますが?実はこの最適化はJEP-180で既に述べられています.あるバケツの中の記録が大きすぎると(現在はTREEIFYUTHRESHOP=8)、HashMapは専用のtreemapを動的に使って置き換えます.このようにした結果が良くなります.悪いO(n)ではなく、O(logn)です.どうやって働いていますか?前に衝突が発生したKEY対応の記録はチェーンの後に簡単に追加されただけで、これらの記録は従来の記録を通してしか調べられません.しかし、このしきい値を超えた後、HashMapはリストを二叉ツリーにアップグレードし、ハッシュ値をツリーの分岐変数として使用し始めました.二つのハッシュ値が同じ桶を指すと、大きいのは右サブツリーに挿入されます.ハッシュ値が等しい場合、HashMapは、key値がComprableインターフェースを実装することが望ましいと考えており、これによって順次挿入することができる.これはhashMapのkeyにとって必要ではないですが、実現すればいいです.このインターフェースが実現されていない場合、深刻なハッシュ衝突が発生した場合、性能向上は期待できません.この性能の向上には何の効果がありますか?例えば悪意のあるプログラムであれば、ハッシュ・アルゴリズムが使用されていることを知っていると、大量の要求を送信し、深刻なハッシュ・衝突を引き起こす可能性がある.そして、これらのkeyにアクセスすることで、サーバーの性能に著しく影響を与え、サービス攻撃を拒否することができます(DoS).JDK 8におけるO(n)からO(logn)への飛躍は、同様の攻撃を効果的に防ぐとともに、HashMap性能の予測可能性を少し強めた.
1.HashMap位置決定と記憶
前のソースコードの分析によって、HashMapはいわゆる「Hashアルゴリズム」を採用して、各要素の記憶位置を決定します.プログラムがput(String,Obect)方法を実行すると、システムはStringを呼び出すhashCode()方法を得て、そのhashCodeの値を得る.JavaオブジェクトごとにhashCode()方法があり、この方法でhashCodeの値を得ることができる.このオブジェクトのhashCode値を取得すると、システムはこのhashCodeの値に基づいてこの要素の格納位置を決定します.ソースは以下の通りです
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
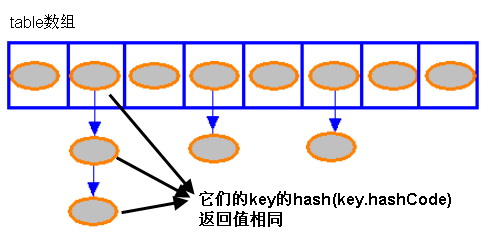
2.Hash衝突発生と解決
Hashmapの中のbucketにはチェーンテーブルの形式が現れています.ハッシュ表で解決する問題の一つはハッシュ値の衝突問題です.チェーン表法は同じsh値の対象をチェーンにしてhash値に対応する溝に置く方法です.オープンアドレス法は、あるスロットビットがすでに占有されている場合に、次の使用可能なスロットビットを探し続ける検出アルゴリズムによって行われる.java.util.hashMapが採用しているチェーンの方式は、チェーンは一方向チェーンです.シングルチェーンテーブルを形成するコアコードは以下の通りです.
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
上記の方法のコードは簡単ですが、システムは常に新しく追加されたEntryオブジェクトをtable配列のbucketIndexインデックスのところに入れます.もしbucketIndexインデックスにEntryオブジェクトが存在したら、新しく追加されたEntryオブジェクトは元のEntryオブジェクトに向けられます.つまり上のプログラムコードのe変数はnull、つまり新しく入れたEntryオブジェクトはnull、つまりEntryチェーンが発生していません. HashMapの中にhash衝突が発生していない時、シングルチェーンテーブルを形成していない時、hashmapは元素を探してとても速くて、get()方法は直接元素に位置することができます.検索したいEntryが見つかるまでは、ちょうど検索するEntryがEntryチェーンの一番端にあるなら、システムは最後まで循環しなければなりません.
以上から分かるように、複数のhashCodeの値が同じ桶に落ちた場合、これらの値はチェーンに格納されている.最悪の場合、すべてのkeyは同じ桶にマッピングされ、hashmapはチェーンに縮退します.検索時間はO(1)からO(n)までです.つまり、私たちはこのHash衝突問題をチェーンで解決します.
3.Hash衝突性能分析
Java 7:hashMapのサイズが大きくなるにつれて、get()法のオーバーヘッドも大きくなります.すべての記録は同じ桶の中の超長いチェーンテーブルの中にあるので、平均的に1つの記録を調べるには半分のリストを巡る必要があります.でも、Java 8の表現はとてもいいです.ロゴの曲線ですので、何桁もの性能が必要です.深刻なハッシュ衝突があっても、最悪の場合ですが、この同じ基準テストはJDK 8における時間の複雑さはO(logn)です.JDK 8の曲線を単独で見るとより明確になります.これは対数線形分布です.
4.Java 8衝突最適化の向上
なぜこのような性能が向上したのですか?ここでは大きなO記号が使われていますが?実はこの最適化はJEP-180で既に述べられています.あるバケツの中の記録が大きすぎると(現在はTREEIFYUTHRESHOP=8)、HashMapは専用のtreemapを動的に使って置き換えます.このようにした結果が良くなります.悪いO(n)ではなく、O(logn)です.どうやって働いていますか?前に衝突が発生したKEY対応の記録はチェーンの後に簡単に追加されただけで、これらの記録は従来の記録を通してしか調べられません.しかし、このしきい値を超えた後、HashMapはリストを二叉ツリーにアップグレードし、ハッシュ値をツリーの分岐変数として使用し始めました.二つのハッシュ値が同じ桶を指すと、大きいのは右サブツリーに挿入されます.ハッシュ値が等しい場合、HashMapは、key値がComprableインターフェースを実装することが望ましいと考えており、これによって順次挿入することができる.これはhashMapのkeyにとって必要ではないですが、実現すればいいです.このインターフェースが実現されていない場合、深刻なハッシュ衝突が発生した場合、性能向上は期待できません.この性能の向上には何の効果がありますか?例えば悪意のあるプログラムであれば、ハッシュ・アルゴリズムが使用されていることを知っていると、大量の要求を送信し、深刻なハッシュ・衝突を引き起こす可能性がある.そして、これらのkeyにアクセスすることで、サーバーの性能に著しく影響を与え、サービス攻撃を拒否することができます(DoS).JDK 8におけるO(n)からO(logn)への飛躍は、同様の攻撃を効果的に防ぐとともに、HashMap性能の予測可能性を少し強めた.