ROSで音声認識、音声合成(openhri_ros)
音声認識、音声合成パッケージ:openhri_ros
OpenRTM-aistで提供されていた音声対話関連モジュールOpenHRIの一部をROSパッケージにしました。
このパッケージでは、Julius、Googleによる音声認識、OpenJTalk、Googleによる音声合成を行うことができます。
このパッケージを利用するためには、audio_captureおよびaudio_playのパッケージが必要になります。
ライセンス
このパッケージは、Eclipse Public License v2.0で開発及び配布しています。
開発リポジトリ
openhri_rosの開発リポジトリは、Githubにあります。
openhri_rosの主な機能
openhri_rosでは、OpenHRI_Voiceにあった機能のうち、
- Juliusを使った音声認識
- Google Cloud Speech-to-Textを使った音声認識(毎月一定量(1h/month)無料)
- OpenJTalkを使った音声合成
- Google Cloud Text-to-Speechを使った音声合成(毎月一定量 無料)
を提供しています。
音声認識と音声合成はあるのですが、対話制御機能は、既に開発済みのeSEAT ver.2.5で対応しています。
したがって、これらをつかうことで、ROSを使った音声対話システムを簡単に作成することができます。
openhri_rosを利用するための準備
openhri_rosでは、音声の入出力(マイクとスピーカー)に関しては、audio_captureおよびaudio_playのノードを使用します。
また、日本語音声認識、日本語音声合成のエンジンとして、Juliusディクテーションキット、OpenJTalkおよびGoogle音声認識、音声合成サービスを使用しています。
各ノードの実装は、Python(現在は、Python2.7で動作確認しています)を使用していますので、下の拡張ライブラリも必要となります。
- pydub
- urllib3
- certifi
- lxml
Juliusディクテーションキットのダウンロードとインストール
Juliusは、大語彙連続日本語音声認識エンジンです。オフィシャルサイトからディクテーションキットをダウンロードし、インストールします。
ダウンロード
下のコマンドを実行すると、直接ダウンロードすることができます。
# cd ~/Downloads
# wget "https://osdn.net/frs/redir.php?m=jaist&f=julius%2F71011%2Fdictation-kit-4.5.zip" -O dictation-kit-4.5.zip
Ubuntuを利用した場合には、aptでjuliusの本体のみインストール可能ですが、日本語認識用の音響モデル、言語モデル、辞書作成ツールなどは、別途用意する必要がありますので、dictation-kitを使うことを推奨しています。
インストール
インストールは、ダウンロードしたアーカイブをunzipコマンドで展開すればいいのですが、openhri_rosのデフォルト設定にあわせて、下のコマンドを実行します。
# sudo mkdir -p /usr/local/julius
# sudo unzip dictation-kit-4.5.zip -d /usr/local/julius
# sudo ln -s /usr/local/julius/dictation-kit-4.5 /usr/local/julius/dictation-kit
以上で、Juliusディクテーションキットのインストールは終了です。
OpenJTalkのインストール
OpenJTalkは、aptコマンドでインストールすることができます。
# sudo apt install open-jtalk open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001
以上で、OpenJTalkのインストールは終了です。
GoogleクラウドサービスのAPIキーの取得
音声認識、音声合成でGoogleのクラウドサービスを利用する場合には、APIキーが必要になります。
Googleクラウドプラットフォームサービスをまだ利用していない場合には、こちらから開始手続きを行ってください。
既に、Googleクラウドプラットフォームサービスを利用しているのであれば、コンソールに移動して、新規プロジェクト(名称は何でも良いのですが、openhri-rosなどで良いと思います)を作成してください。詳細な作成方法に関しては、オフィシャルドキュメントを参照して下さい。
プロジェクトを作って、コンソールにアクセスすると下のようなダッシュボードが現れます。
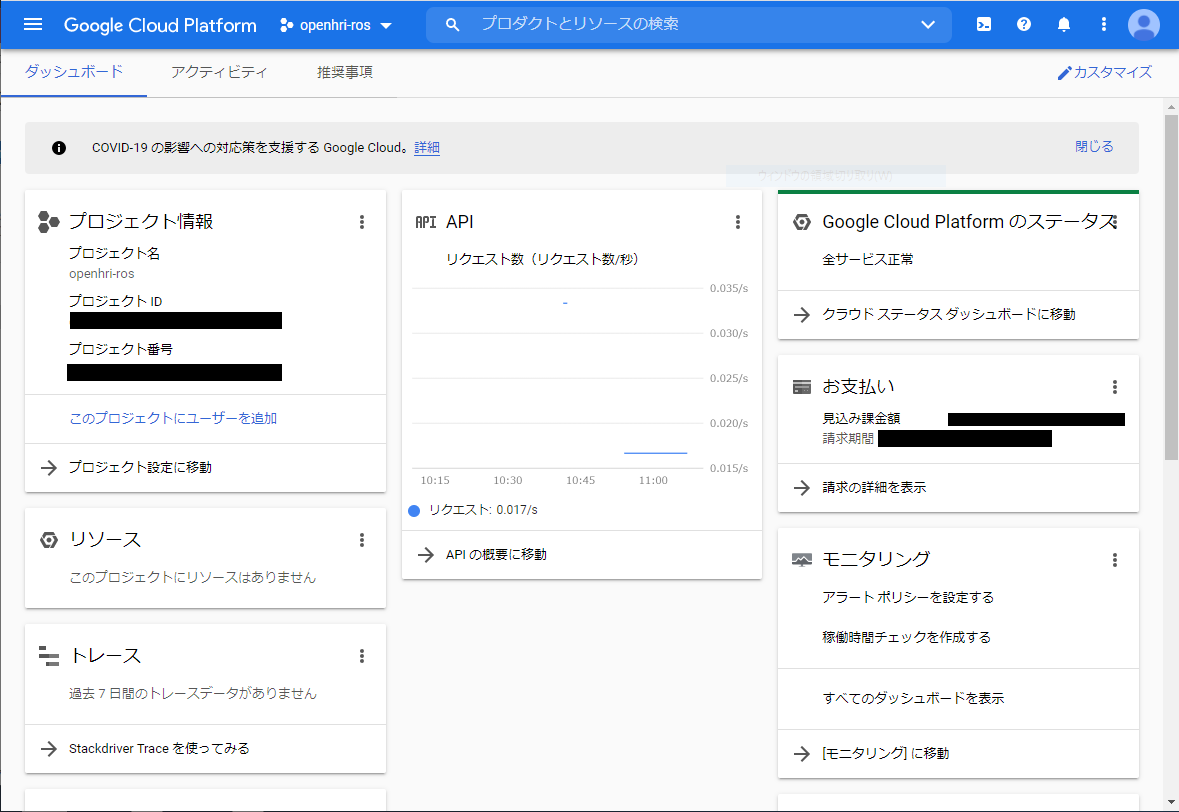
ここで、真ん中にある 「APIの概要に移動」をクリックして、「APIとサービス」のダッシュボードに移動します。
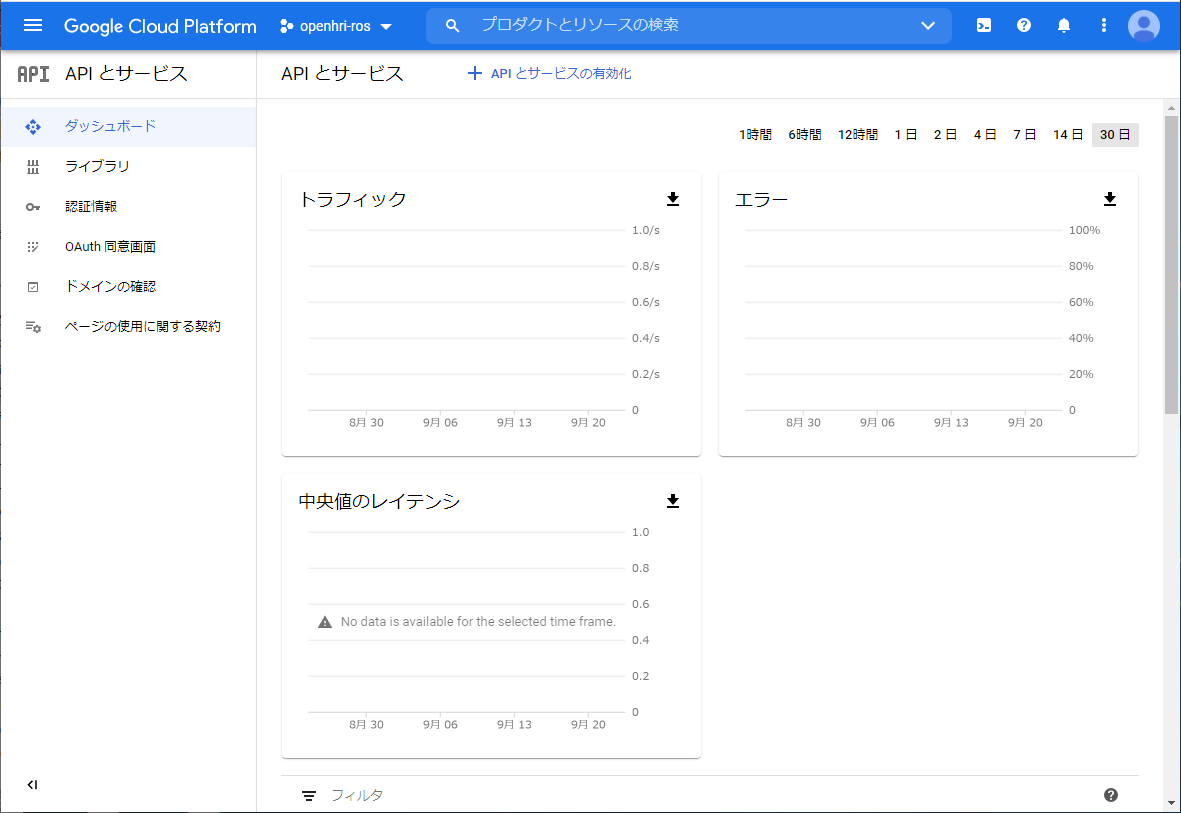
次に、音声認識と音声合成に必要なAPIとサービスを有効化します。真ん中上部の「+APIとサービスの有効化」をクリックします。
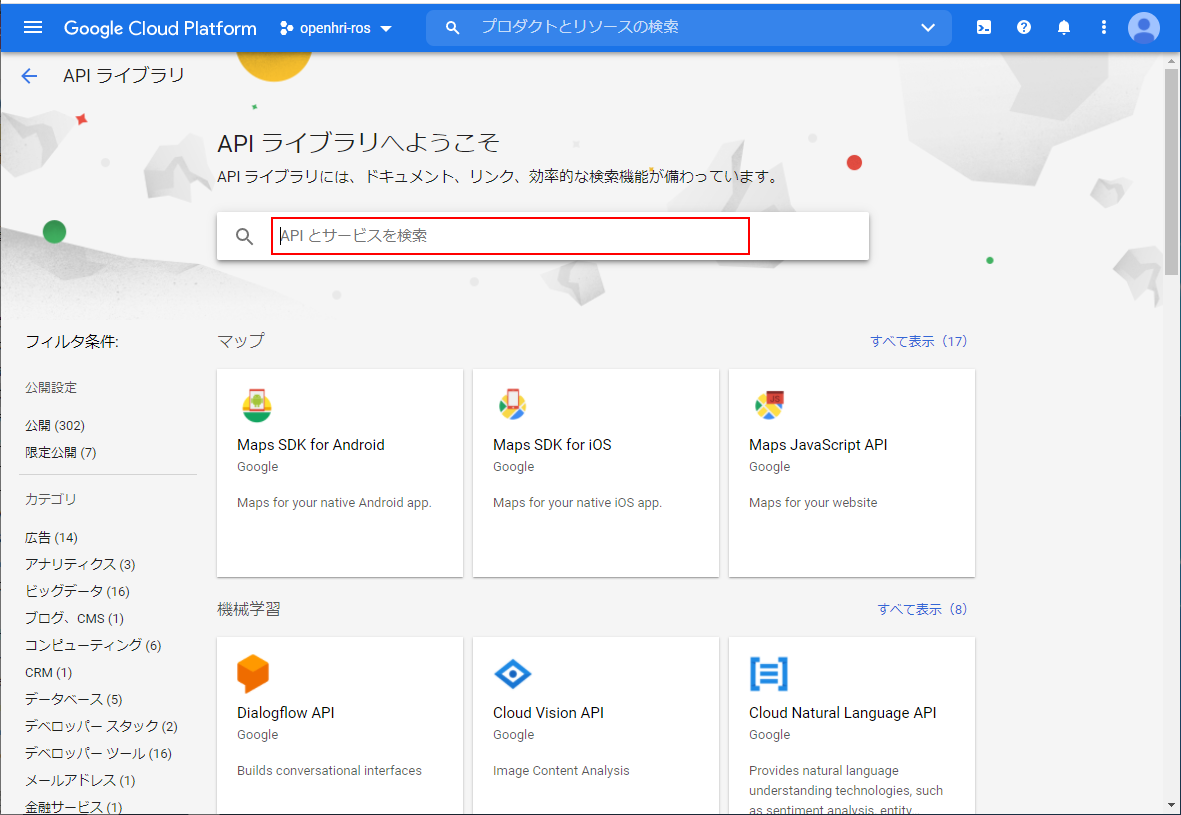
ここで、音声認識(Cloud Speech-to-Text API)と音声合成(Cloud Text-to-Speech API)のサービスを検索して、有効化してください。ここで、音声合成の方は、検索窓から検索しないと選択できないようです。(カテゴリの設定がありません)
それぞれのAPIを有効にしたら、ダッシュボードに戻って「認証情報」を作成します。下図のように真ん中上部の「+認証情報作成」が表示されていない場合には、「OAuth2.0の認証」が必要になりますので、画面の表示に従って入力していきます。
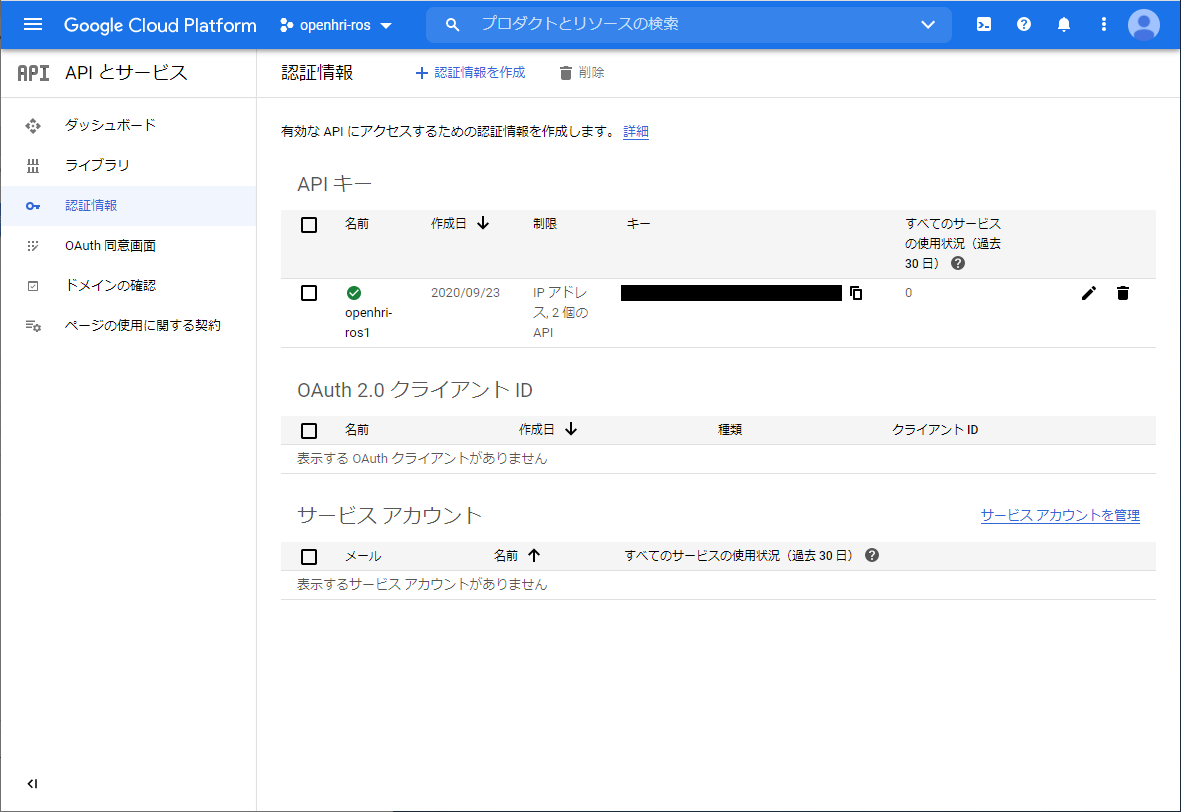
「+認証情報作成」をクリックすると下図のようにプルダウンメニューがでますので「APIキー」を選択してください。
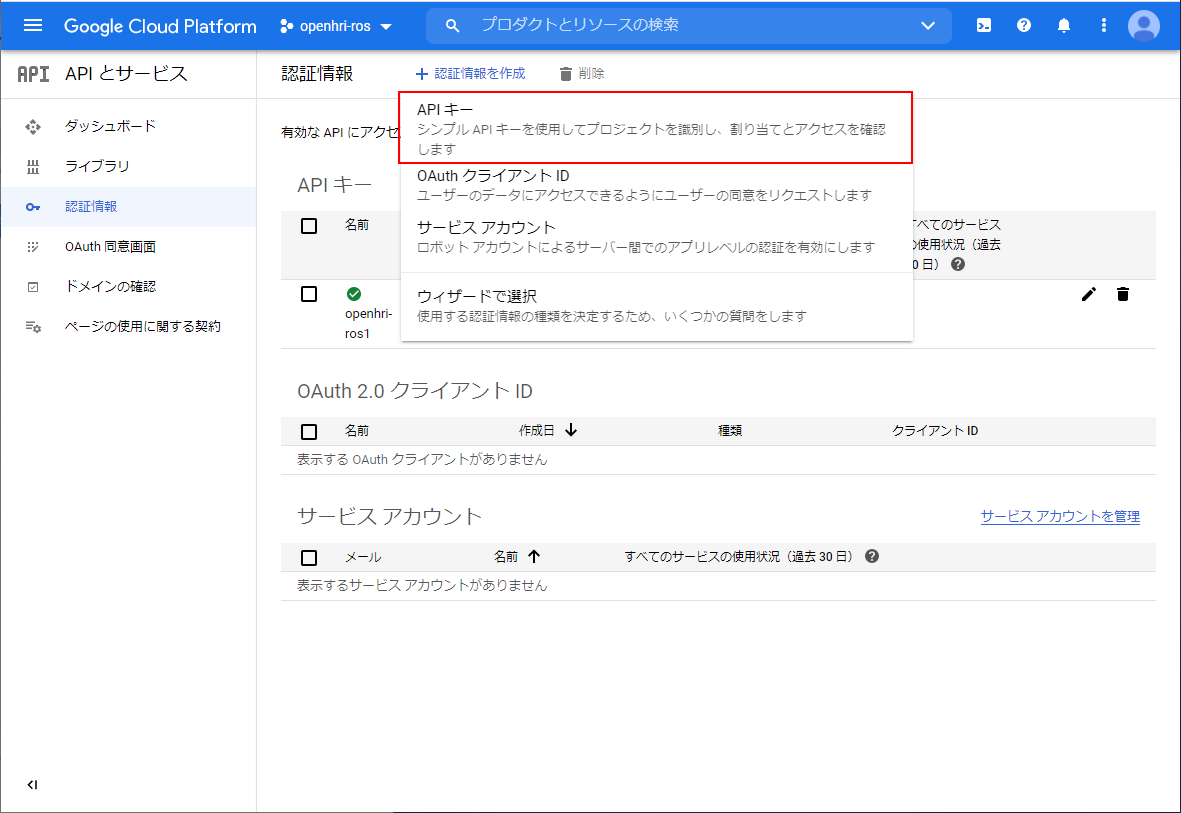
下図のように、APIキーが表示されれば、あとは必要に応じて、利用制限を付加してください。
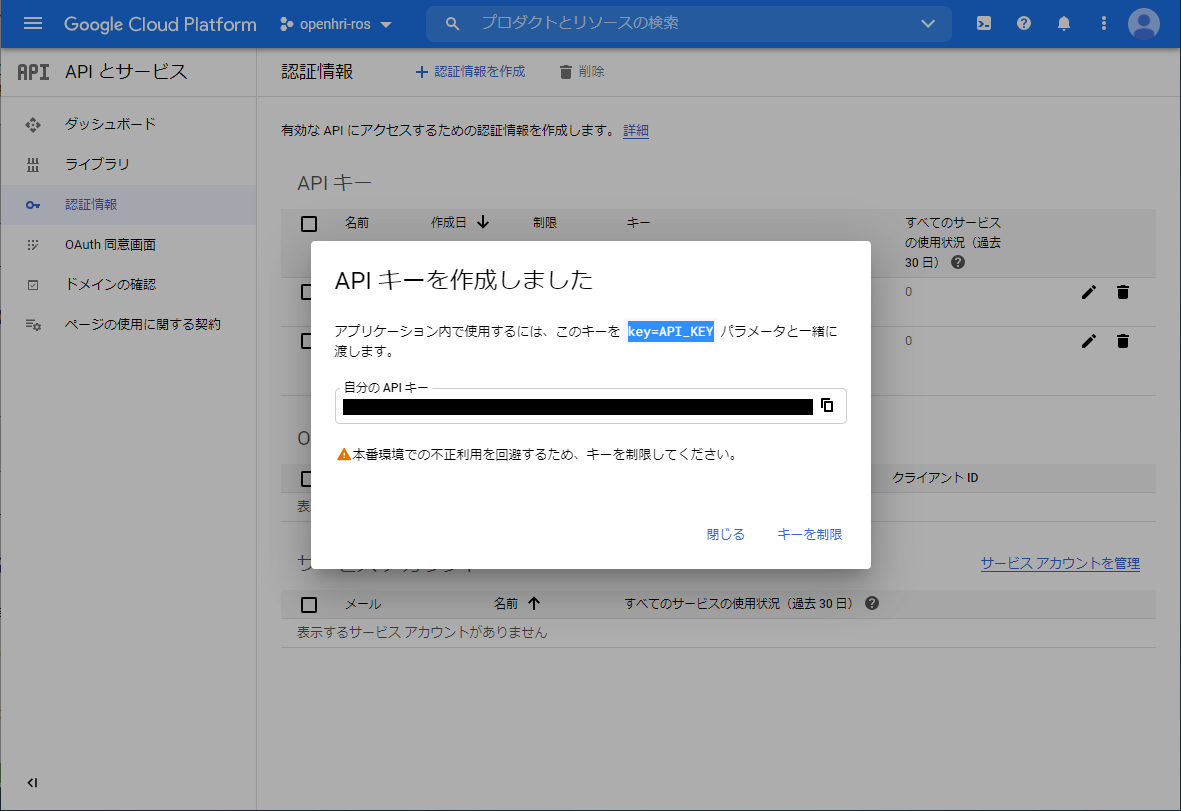
ここで表示されたAPIキーは、openhri_rosで使用しますので、メモをしておきます。
APIキーの保存
openhri_rosでGoogleクラウドサービスを利用するために、先ほどのAPIキーを記載したファイル(google_apikey.txt)を作成します。
このファイル名は、openhri_rosのデフォルト設定です。
次にこのファイルを ~/.openhri というディレクトリを作成して、その下に保存してください。
# mkdir ~/.openhri
# echo 'APIキー' > ~/.openhri/google_apikey.txt
以上で、Googleクラウドサービスを使うための設定は終了です。
その他のライブラリのインストール
openhri_rosでは、いくつかのPythonライブラリが必要になります。
下のコマンドでインストールしてください。
# sudo apt install python-pydub python-urllib3 python-certifi python-lxml ros-melodic-audio-capture ros-melodic-audio-play
また、JuliusをWebサービスとして起動させる場合には、python-daemonも必要になります。
openhri_rosのダウンロードとインストール
openhri_rosは、通常のROSパッケージと同じように、catkinビルドシステムに対応しています。
リポジトリからダウンロードして、ビルドしてください。
# source /opt/ros/melodic/setup.bash
# mkdir -p ~/catkin_ws/src
# cd ~/catkin_ws/src
# catkin_init_workspace
# git clone https://github.com/haraisao/openhri_ros
# cd ~/catkin_ws
# catkin_make
# souece devel/setup.bash
以上で、openhri_rosの準備完了です。
openhri_rosの実行
上記の設定が終われば、デフォルト設定の状態で、roslaunchでテスト実行することができます。
現在作成済みのlaunchファイルは、
- google_asr.launch
- Google Speech-to-Textで音声認識を行います。結果は、'/asr/result' で配信されます。 結果は、XML形式なので、適当な処理が必要です。eSEATであれば、その出力が使えるはずです。
- google_tts.launch
- Google Text-to-Speechで音声合成を行います。'/tts/data'(std_msgs/String)に文字列を配信すると読み上げます。
- julius.launch
- Julius(dictation)を使って音声認識を行います。結果は、'/julius/result' で配信されます。 結果は、XML形式なので、適当な処理が必要です。eSEATであれば、その出力が使えるはずです。
- openjtalk.launch
- OpenJTalkで音声合成を行います。'/tts/data'(std_msgs/String)に文字列を配信すると読み上げます。
Author And Source
この問題について(ROSで音声認識、音声合成(openhri_ros)), 我々は、より多くの情報をここで見つけました https://qiita.com/haraisao/items/06e0846cbe596839e09f著者帰属:元の著者の情報は、元のURLに含まれています。著作権は原作者に属する。
Content is automatically searched and collected through network algorithms . If there is a violation . Please contact us . We will adjust (correct author information ,or delete content ) as soon as possible .