Azure Machine Learningで始まる最良の方法
13911 ワード
私は、自分自身を含む多くのデータ科学者を知っています.そして、その人は、Jupyterノートまたは若干のPython IDEを通して、GPUで可能にされたマシン(ローカルか雲のどちらか)で大部分の彼らの仕事をします.AI/MLソフトウェアエンジニアとしての私の2年の間に、私がしていたものである、GPUなしで1台のマシンでデータを準備して、それから、トレーニングをするために、GPU VMを雲で使ってください.
一方、あなたはおそらくAzure Machine Learning - しかし、あなたが何かを見始めるならば、プラットホームサービスgetting started tutorials , あなたはAzure MLを使用することは多くの不必要なオーバーヘッドを作成するという印象を持ちます、そして、プロセスは理想的でありません.たとえば、上記の例のトレーニングスクリプトは、1つのJupyterセルでテキストファイルとして作成されます.コード補完なしで、またはローカルまたはデバッグを実行する便利な方法です.この余分なオーバーヘッドは、我々が我々のプロジェクトであまりそれを使わなかった理由でした.
しかし、最近私はVisual Studio Code Extension for Azure ML . この拡張機能を使用すると、VSコードでトレーニングコードの右側を開発することができますし、ローカルで実行し、ボタンをクリックするだけでクラスタ上で訓練するために同じコードを提出することができます.そうすることで、いくつかの重要な利点を達成できます. あなたのマシン上でローカルのほとんどの時間を費やすことができるし、トレーニングのためだけに強力なGPUリソースを使用します.トレーニングクラスタは自動的に需要に応じて変更することができますし、必要に応じてVMをスピンすることができます0にマシンの最小量を設定することによって. あなたは、1つの中央の場所でのメトリックと作成モデルを含むあなたのトレーニングのすべての結果を維持する-必要はありません手動で各実験のための精度の記録を維持する. いくつかの人々が同じプロジェクトで働くならば、彼らは同じクラスタを使用することができます(すべての実験は待ち行列に入れられます)、そして、彼らは互いの実験結果を見ることができます.たとえば、あなたは教室環境でAzure MLを使用することができます、そして、各々の学生に個々のGPU機械を与える代わりに、あなたは誰にでも役立つ一つのクラスタをつくることができて、モデル精度の学生の間で競争を促進することができます. あなたがHyperParameters最適化のために例えば多くのトレーニングを実行する必要があるならば、すべてのそれはちょうど少数の命令でされることができます. 私は、あなたがAzure MLを試みることを確信していることを望みます!ここでは、最善の方法を開始します. インストールVisual Studio Code , Azure Sign In and Azure ML 拡張 リポジトリをクローンするhttps://github.com/CloudAdvocacy/AzureMLStarter - これは、MNISTの数字を認識するモデルを訓練するいくつかのサンプルコードが含まれます.その後、VSコードでクローン化されたリポジトリを開くことができます. 記事を読む!
Azure MLのすべてはワークスペースのまわりで組織されます.それはあなたの実験を提出し、データと結果のモデルを格納する中心点です.また、特別なAzure ML Portal それはあなたのワークスペースのためのWebインターフェイスを提供し、そこから多くの操作を実行することができます、あなたの実験やメトリックなどを監視します.
ワークスペースを作成するにはAzure Portal Webインターフェースstep-by-step instructions ), またはazure cliを使うinstructions ):
我々の例では、我々は非常に解決する方法を示しますtraditional problem of handwritten digit recognition MNISTデータセットの使用同様に、他のトレーニングスクリプトを自分で実行することができます.
我々のサンプルリポジトリは、シンプルなMNISTのトレーニングスクリプトが含まれて
このスクリプトをローカルで実行し、結果を見ることができます.しかしながら、私たちがAzure MLを使用することを選んだなら、それは私たちに2つの大きな利益を与えます: ローカル計算機リソースに対するスケジューリングとランニングトレーニング.Azure MLはスクリプトを適切な設定でDockerコンテナに梱包することに注意します Azure MLワークスペース内の集中位置にトレーニングの結果をログ出力します.そのためには、スクリプトに以下の行のコードを追加する必要があります.
AVSからVSコードまで実行するには、次の手順に従います. Azure拡張モジュールがクラウドアカウントに接続されていることを確認します.左側のメニューのAzureアイコンを選択します.接続されていない場合は、接続する権利を提供する右下の通知が表示されます.see picture ). それをクリックし、ブラウザを介してログインします.また、Ctrl - Shift - Pキーを押してコマンドパレットを作成し、Azure sign inに入力できます. その後、Azure Barのマシンラーニングセクションでワークスペースを見ることができます.

ここでは、あなたのワークスペースの中に異なるオブジェクトを見るべきです. ファイルのリストに戻って

Azureサブスクリプションとワークスペースを確認し、「新規作成」を選択します.



新しい計算と設定の作成
Computeは、トレーニング/推論に使用されるコンピューティングリソースを定義します.ローカルマシン、または任意のクラウドリソースを使用できます.この例では、amlComputeクラスタを使用します.min = 0とmax = 4ノードで、標準のDS 3 CANV 2マシンのスケーラブルなクラスタを作成してください.あなたはどちらかのコードインターフェイスから、またはML Portal .

Compute構成は、リモートリソース上でのトレーニングを行うために作成されたコンテナのオプションを定義します.特に、それはインストールされるべきすべてのライブラリを指定します.SkLearnを選択し、ライブラリの一覧を確認します.


次に、次の実験のJSON記述を持つウィンドウが表示されます.たとえば、実験やクラスタ名を変更し、いくつかのパラメータを微調整するなどの情報を編集することができます.準備ができたら、提出実験をクリックします.

実験が首尾よくVSコードで提出されたあと、あなたはAzure ML Portal 実験の進捗と結果を持つページ.

また、実験タブからあなたの実験を見つけることができますAzure ML Portal , またはAVSマシンの学習バーから

コード内のパラメータを調整した後に再度実験を実行したい場合は、このプロセスははるかに速くなりやすくなります.あなたのトレーニングファイルを右クリックすると、新しいメニューオプションを繰り返し実行されます-ちょうどそれを選択し、実験がすぐに提出されます.

次に、上記のスクリーンショットのように、Azure MLポータル上のすべての実行からメトリック結果が表示されます. 現在、あなたはAzure MLへの提出が実行されないことを知っています、そして、あなたはいくつかのグッズ(あなたの実行、モデルなどからすべての統計を格納するように)を無料で得ます.
私たちの場合、クラスタ上で実行されるスクリプトがローカルに実行されている以上の時間がかかることに気がつきました.もちろん、スクリプトやスクリプト内のすべての環境をパッケージングする際にオーバーヘッドがあり、それをクラウドに送ります.クラスタが自動的に0ノードまでスケールダウンするように設定されている場合、VM起動のためにいくつかの追加オーバーヘッドがあるかもしれません.しかし、実際の生活のシナリオでは、トレーニングが数分かかり、時にはより多くの場合-このオーバーヘッドはかろうじて重要になる、特にクラスタから取得することを期待することができます速度の改善を与えた.
リモートクラスタ上で実行するスクリプトをどのように提出するかを知っているので、日常の作業でAzure MLを利用し始めることができます.それはあなたが通常のPC上でスクリプトを開発することができますし、GPU VMまたはクラスタの実行のために自動的に1つの場所ですべての結果を維持するためのスケジュールを設定します.
しかし、これらの2つよりazure mlを使用するより多くの利点があります.Azure MLはデータストレージとデータセット処理にも使用できます.異なるトレーニングスクリプトが同じデータにアクセスするのは簡単です.また、パラメータを変えて、APIを通して自動的に実験を提出することができます.また、Azure MLと呼ばれる特定の技術があるHyperdrive , これは、より賢いパラメータの検索を行います.私は次のポストでこれらの機能と技術についてもっと話します.
マイクロソフトから以下のコースを見つけることができます. Introduction to Azure Machine Learning Service Building AI Solutions with Azure ML Service Training Local Models with Azure ML Service
一方、あなたはおそらくAzure Machine Learning - しかし、あなたが何かを見始めるならば、プラットホームサービスgetting started tutorials , あなたはAzure MLを使用することは多くの不必要なオーバーヘッドを作成するという印象を持ちます、そして、プロセスは理想的でありません.たとえば、上記の例のトレーニングスクリプトは、1つのJupyterセルでテキストファイルとして作成されます.コード補完なしで、またはローカルまたはデバッグを実行する便利な方法です.この余分なオーバーヘッドは、我々が我々のプロジェクトであまりそれを使わなかった理由でした.
しかし、最近私はVisual Studio Code Extension for Azure ML . この拡張機能を使用すると、VSコードでトレーニングコードの右側を開発することができますし、ローカルで実行し、ボタンをクリックするだけでクラスタ上で訓練するために同じコードを提出することができます.そうすることで、いくつかの重要な利点を達成できます.
ワークスペースとポータル
Azure MLのすべてはワークスペースのまわりで組織されます.それはあなたの実験を提出し、データと結果のモデルを格納する中心点です.また、特別なAzure ML Portal それはあなたのワークスペースのためのWebインターフェイスを提供し、そこから多くの操作を実行することができます、あなたの実験やメトリックなどを監視します.
ワークスペースを作成するにはAzure Portal Webインターフェースstep-by-step instructions ), またはazure cliを使うinstructions ):
az extension add -n azure-cli-ml
az group create -n myazml -l northeurope
az ml workspace create -w myworkspace -g myazml
トレーニングスクリプト
我々の例では、我々は非常に解決する方法を示しますtraditional problem of handwritten digit recognition MNISTデータセットの使用同様に、他のトレーニングスクリプトを自分で実行することができます.
我々のサンプルリポジトリは、シンプルなMNISTのトレーニングスクリプトが含まれて
train_local.py . このスクリプトはOpenMLからMNISTデータセットをダウンロードし、SkLearnを使用しますLogisticRegression モデルを訓練し、結果の精度を出力します.mnist = fetch_openml('mnist_784')
mnist['target'] = np.array([int(x) for x in mnist['target']])
shuffle_index = np.random.permutation(len(mist['data']))
X, y = mnist['data'][shuffle_index], mnist['target'][shuffle_index]
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size = 0.3, random_state = 42)
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_hat = lr.predict(X_test)
acc = np.average(np.int32(y_hat == y_test))
print('Overall accuracy:', acc)
スクリプトの実行
このスクリプトをローカルで実行し、結果を見ることができます.しかしながら、私たちがAzure MLを使用することを選んだなら、それは私たちに2つの大きな利益を与えます:
from azureml.core.run import Run
...
try:
run = Run.get_submitted_run()
run.log('accuracy', acc)
except:
pass
train_universal.py (上記のコードより少し複雑です).ローカルで( azure MLなしで)、リモート計算リソースを実行することもできます.AVSからVSコードまで実行するには、次の手順に従います.
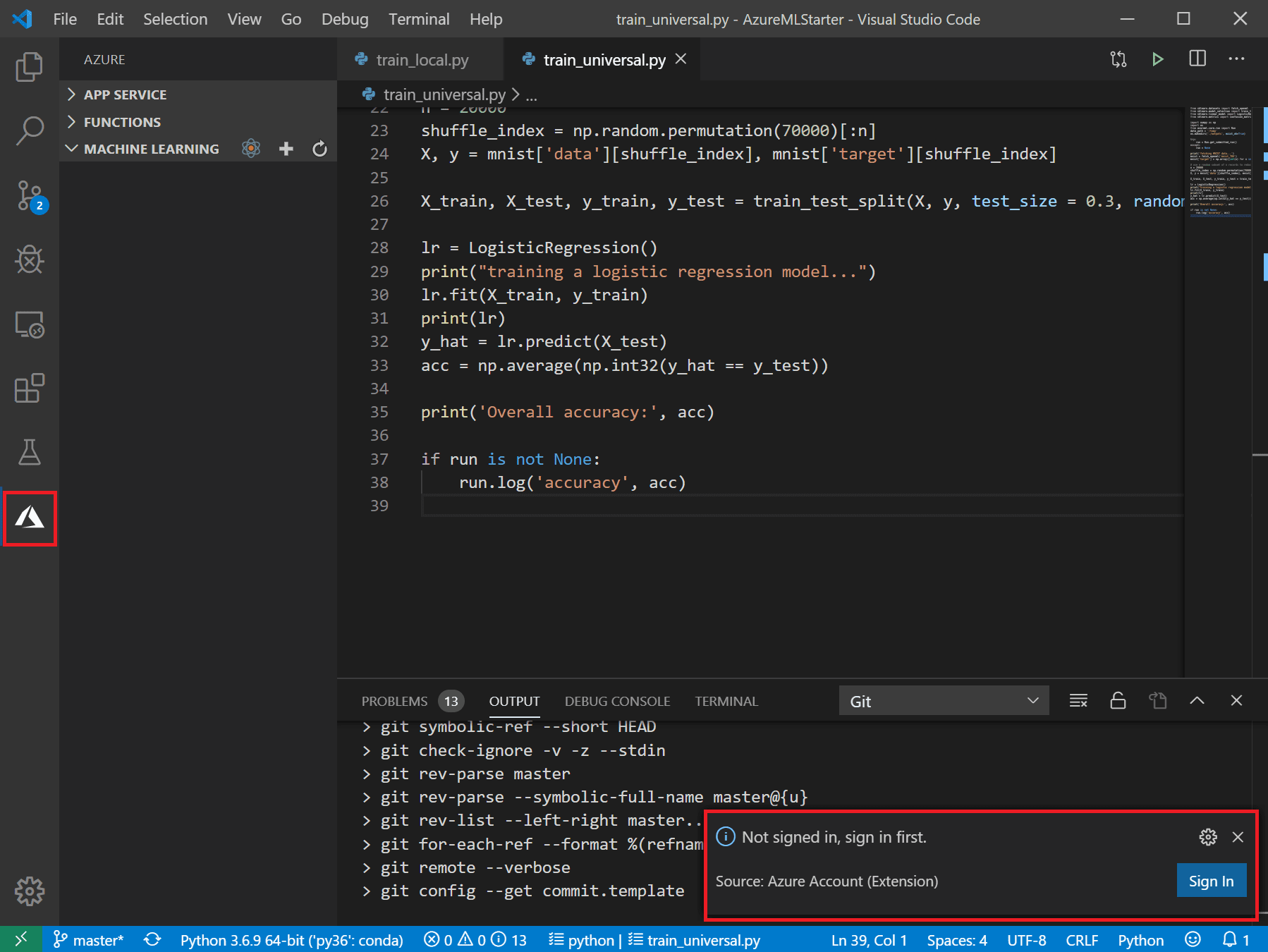{kind=link}
ここでは、あなたのワークスペースの中に異なるオブジェクトを見るべきです.
train_universal.py とAzure MLを選択します. 新しい計算と設定の作成
Computeは、トレーニング/推論に使用されるコンピューティングリソースを定義します.ローカルマシン、または任意のクラウドリソースを使用できます.この例では、amlComputeクラスタを使用します.min = 0とmax = 4ノードで、標準のDS 3 CANV 2マシンのスケーラブルなクラスタを作成してください.あなたはどちらかのコードインターフェイスから、またはML Portal .
Compute構成は、リモートリソース上でのトレーニングを行うために作成されたコンテナのオプションを定義します.特に、それはインストールされるべきすべてのライブラリを指定します.SkLearnを選択し、ライブラリの一覧を確認します.
また、実験タブからあなたの実験を見つけることができますAzure ML Portal , またはAVSマシンの学習バーから
次に、上記のスクリーンショットのように、Azure MLポータル上のすべての実行からメトリック結果が表示されます.
私たちの場合、クラスタ上で実行されるスクリプトがローカルに実行されている以上の時間がかかることに気がつきました.もちろん、スクリプトやスクリプト内のすべての環境をパッケージングする際にオーバーヘッドがあり、それをクラウドに送ります.クラスタが自動的に0ノードまでスケールダウンするように設定されている場合、VM起動のためにいくつかの追加オーバーヘッドがあるかもしれません.しかし、実際の生活のシナリオでは、トレーニングが数分かかり、時にはより多くの場合-このオーバーヘッドはかろうじて重要になる、特にクラスタから取得することを期待することができます速度の改善を与えた.
次は何ですか。
リモートクラスタ上で実行するスクリプトをどのように提出するかを知っているので、日常の作業でAzure MLを利用し始めることができます.それはあなたが通常のPC上でスクリプトを開発することができますし、GPU VMまたはクラスタの実行のために自動的に1つの場所ですべての結果を維持するためのスケジュールを設定します.
しかし、これらの2つよりazure mlを使用するより多くの利点があります.Azure MLはデータストレージとデータセット処理にも使用できます.異なるトレーニングスクリプトが同じデータにアクセスするのは簡単です.また、パラメータを変えて、APIを通して自動的に実験を提出することができます.また、Azure MLと呼ばれる特定の技術があるHyperdrive , これは、より賢いパラメータの検索を行います.私は次のポストでこれらの機能と技術についてもっと話します.
有用資源
マイクロソフトから以下のコースを見つけることができます.
Reference
この問題について(Azure Machine Learningで始まる最良の方法), 我々は、より多くの情報をここで見つけました https://dev.to/azure/the-best-way-to-start-with-azure-machine-learning-17jlテキストは自由に共有またはコピーできます。ただし、このドキュメントのURLは参考URLとして残しておいてください。
Collection and Share based on the CC Protocol