フットボールを作る⚽) ノードとトリビアボット.JSと操り人形
また、投稿https://virenb.cc/footbot
これらはTwitterボットを構築する上で私のメモです.それは私が数ヶ月前に構築したものであり、私はそれが他の誰かを助けることができればそれを文書化したいだけです.Twitterのボットは、非常に人気のあるプロジェクト(そこにあるすべての他のブログの記事によって判断)、それは自分のポートフォリオに良い追加されるようだ.
このプロジェクトの私のモチベーションは新しいものを構築し、新しいツールで作業することでしたPuppeteer ), そして、私の情熱(サッカー/フットボールとプログラミング)の私の2つを結合してください.
では、始めましょう.
私がこのプロジェクトに使用した技術は、
- Node.js
- Puppeteer
- Twit (Twitter API Client)
- GitHub Actions
- Wikipedia.org
任意のコードを書く前に、あなたのロボット(または任意のプロジェクト)を達成するために必要なものを確立することが重要です.私は、私のTwitterボットから単純な出力が欲しかったです.私はトリビアの質問(サッカー選手のバイオのWikipediaのスクリーンショット)つぶやきをして答えをつぶやき、数時間後にサッカー選手の名前を明らかにしたい.さて、実際のプロジェクトに.
あなたのコマンドラインで「NPM Init」を書く前に、私はアプリケーションを登録するために行きました.APIキー、API秘密、アクセストークン、およびアクセストークン秘密が必要になります.ちょうどあなたのアプリケーションに関するいくつかの情報と詳細を入力する必要があります.
一度あなたのTwitterのアプリケーションが承認されると、プロジェクトにAPIキーとアクセストークン情報を追加するに戻ることができます.

さて、次のツイートのドキュメントを探索することができますので、我々はボットのつぶやきを得ることができる、いくつかの“ハローワールド”アクションを開始します.
https://github.com/ttezel/twit
多くはこのAPIで行うことができます.あなたのTwitterのボットつぶやき、検索、フォロワー、ポストメディアなどを得ることができます.
あなたのボットを起動するプロジェクトからいくつかのコードをコピーすることができます.

わかりました.我々は、作業Twitterボットがあります.我々の目標がメディア(Wikipediaスクリーンショット)を掲示することになっているので、我々は間違いなく再びそれらの医者を参照しています.
だから、私たちが残したものは、
ウィキペディアから情報を取得
スクリーンショットを撮る
画像をつぶやく
-展開する.
プロジェクト、ウィキペディアの情報部分に移動!
https://en.wikipedia.org/wiki/Romelu_Lukaku
上記のリンクは、我々が使用しているウィキペディアの例です.
右側のインフォメーションボックスに興味があります.我々のボットは、名前、写真、情報(名前、年齢など)、ちょうどチーム情報なしでイメージをつぶやきます.私たちの'答え'つぶやきは、すべての情報をボックスのイメージがあります.
私たちは、ブラウザのdevtoolsに頼る必要があります.

次のステップはどのように質問つぶやきの情報を取り除くために決定することでした.ブラウザのdevtoolsを使って、ページ上のHTMLを見ることができました.それから、たくさんのバニラJavaScriptメソッドが来ました.
https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector
https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelectorAll
https://developer.mozilla.org/en-US/docs/Web/API/Node/parentNode
https://developer.mozilla.org/en-US/docs/Web/API/ChildNode/remove
https://developer.mozilla.org/en-US/docs/Web/API/Node/nextSibling

上記のコードを実行した後、スクリーンショットは次のようになります.

それは私が行っていた'トリビア'の側面だった.ユーザーがフットボール選手のチームを見ることができるが、他の情報から推測すること.
だから今、我々は必要なデータを持って、どのように実際にそれぞれの画像のスクリーンショットを取るのですか?おじさん!これは私の初めてこのツールを使用した.
操り人形ウェブサイトから.
これらはTwitterボットを構築する上で私のメモです.それは私が数ヶ月前に構築したものであり、私はそれが他の誰かを助けることができればそれを文書化したいだけです.Twitterのボットは、非常に人気のあるプロジェクト(そこにあるすべての他のブログの記事によって判断)、それは自分のポートフォリオに良い追加されるようだ.
このプロジェクトの私のモチベーションは新しいものを構築し、新しいツールで作業することでしたPuppeteer ), そして、私の情熱(サッカー/フットボールとプログラミング)の私の2つを結合してください.
では、始めましょう.
私がこのプロジェクトに使用した技術は、
- Node.js
- Puppeteer
- Twit (Twitter API Client)
- GitHub Actions
- Wikipedia.org
任意のコードを書く前に、あなたのロボット(または任意のプロジェクト)を達成するために必要なものを確立することが重要です.私は、私のTwitterボットから単純な出力が欲しかったです.私はトリビアの質問(サッカー選手のバイオのWikipediaのスクリーンショット)つぶやきをして答えをつぶやき、数時間後にサッカー選手の名前を明らかにしたい.さて、実際のプロジェクトに.
あなたのコマンドラインで「NPM Init」を書く前に、私はアプリケーションを登録するために行きました.APIキー、API秘密、アクセストークン、およびアクセストークン秘密が必要になります.ちょうどあなたのアプリケーションに関するいくつかの情報と詳細を入力する必要があります.
mkdir footbot
cd footbot
npm init -yNYプロジェクトの初期化を開始します.次に、ファイルを作成しました.私のプロジェクトフォルダーで.touch server.js私は先に行き、私が必要とするすべてのパッケージをインストールします.npm install dotenv
npm install puppeteer
npm install twit
一度あなたのTwitterのアプリケーションが承認されると、プロジェクトにAPIキーとアクセストークン情報を追加するに戻ることができます.
touch .env隠しファイルを作ります.env、この情報を格納する.あなた.envファイルはこのようになります.// .env
CONSUMER_KEY=copypaste
CONSUMER_SECRET=theinformation
ACCESS_TOKEN=intothis
ACCESS_TOKEN_SECRET=file
さて、次のツイートのドキュメントを探索することができますので、我々はボットのつぶやきを得ることができる、いくつかの“ハローワールド”アクションを開始します.
https://github.com/ttezel/twit
多くはこのAPIで行うことができます.あなたのTwitterのボットつぶやき、検索、フォロワー、ポストメディアなどを得ることができます.
あなたのボットを起動するプロジェクトからいくつかのコードをコピーすることができます.
// server.js
const Twit = require('twit')
const T = new Twit({
consumer_key: '...',
consumer_secret: '...',
access_token: '...',
access_token_secret: '...',
})
// tweet 'hello world!'
//
T.post('statuses/update', { status: 'hello world!' }, function(err, data, response) {
console.log(data)
})
require('dotenv').config();
const consumer_key = process.env.CONSUMER_KEY;
const consumer_secret = process.env.CONSUMER_SECRET;
const access_token = process.env.ACCESS_TOKEN;
const access_token_secret = process.env.ACCESS_TOKEN_SECRET;
const T = new Twit({
consumer_key,
consumer_secret,
access_token,
access_token_secret,
});
// tweet 'hello world!'
T.post('statuses/update', { status: 'hello world!' }, function(err, data, response) {
console.log(data)
})
"scripts": {
"start": "node server.js"
},
npm run start , 我々のロボットは、『Hello World』からつぶやきます.
わかりました.我々は、作業Twitterボットがあります.我々の目標がメディア(Wikipediaスクリーンショット)を掲示することになっているので、我々は間違いなく再びそれらの医者を参照しています.
だから、私たちが残したものは、
ウィキペディアから情報を取得
スクリーンショットを撮る
画像をつぶやく
-展開する.
プロジェクト、ウィキペディアの情報部分に移動!
https://en.wikipedia.org/wiki/Romelu_Lukaku
上記のリンクは、我々が使用しているウィキペディアの例です.
右側のインフォメーションボックスに興味があります.我々のボットは、名前、写真、情報(名前、年齢など)、ちょうどチーム情報なしでイメージをつぶやきます.私たちの'答え'つぶやきは、すべての情報をボックスのイメージがあります.
私たちは、ブラウザのdevtoolsに頼る必要があります.
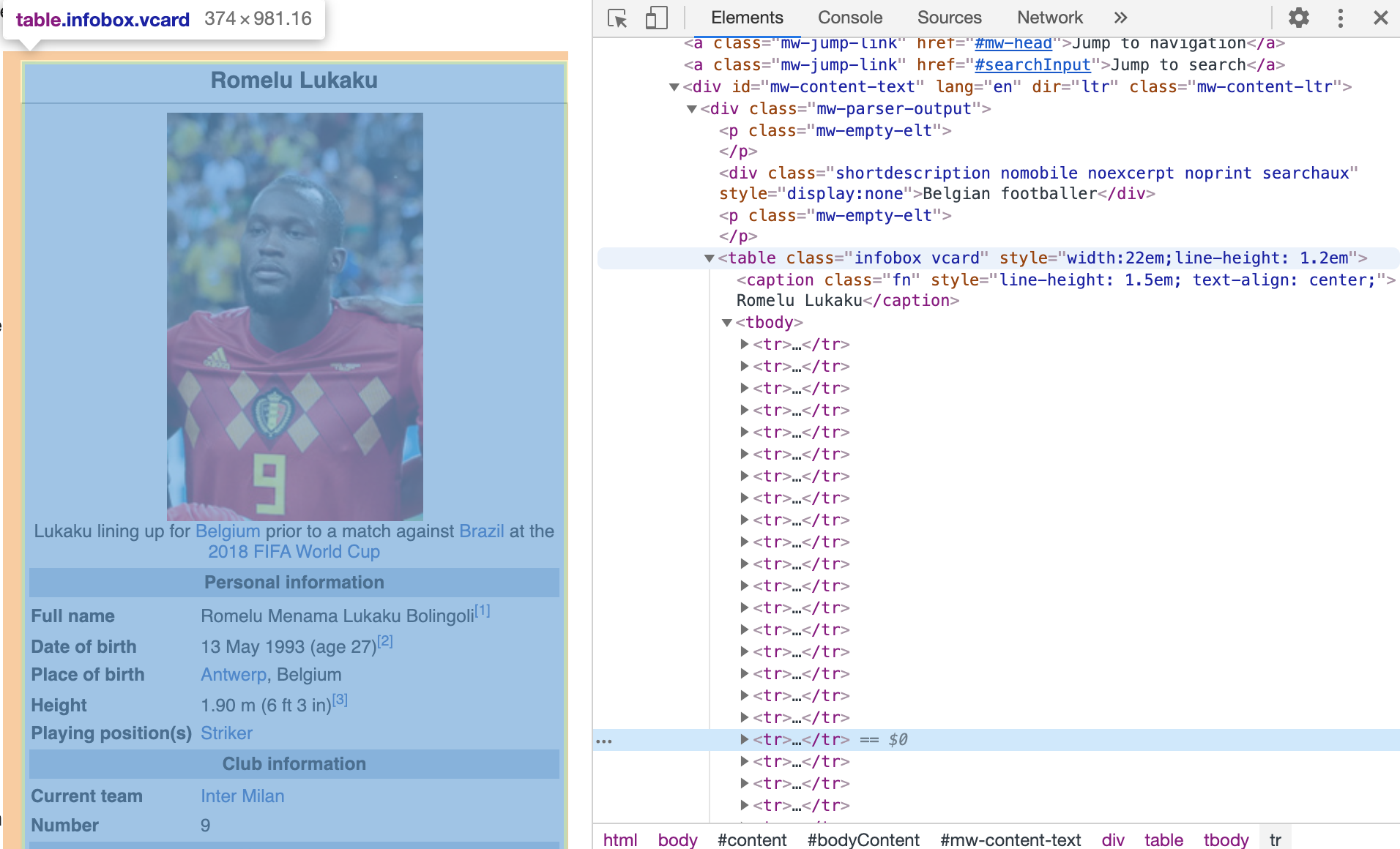
次のステップはどのように質問つぶやきの情報を取り除くために決定することでした.ブラウザのdevtoolsを使って、ページ上のHTMLを見ることができました.それから、たくさんのバニラJavaScriptメソッドが来ました.
https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector
https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelectorAll
https://developer.mozilla.org/en-US/docs/Web/API/Node/parentNode
https://developer.mozilla.org/en-US/docs/Web/API/ChildNode/remove
https://developer.mozilla.org/en-US/docs/Web/API/Node/nextSibling
let img = document.querySelector('.image');
let nickname = document.querySelector('.nickname');
let age = document.querySelector('.ForceAgeToShow');
let bplace = document.querySelector('.birthplace');
let role = document.querySelector('.role');
let org = document.querySelector('.org');
if (img) img.parentNode.remove();
if (nickname) nickname.parentNode.remove();
age.parentNode.parentNode.remove();
bplace.parentNode.nextSibling.remove();
bplace.parentNode.remove();
role.parentNode.remove();
if (org.parentNode.nextSibling) org.parentNode.nextSibling.remove();
if (org) org.parentNode.remove();
let birthname = document.querySelector('.nickname');
if (birthname) {
birthname.parentNode.remove();
}
let fullname = document.querySelector('.fn');
fullname.remove();
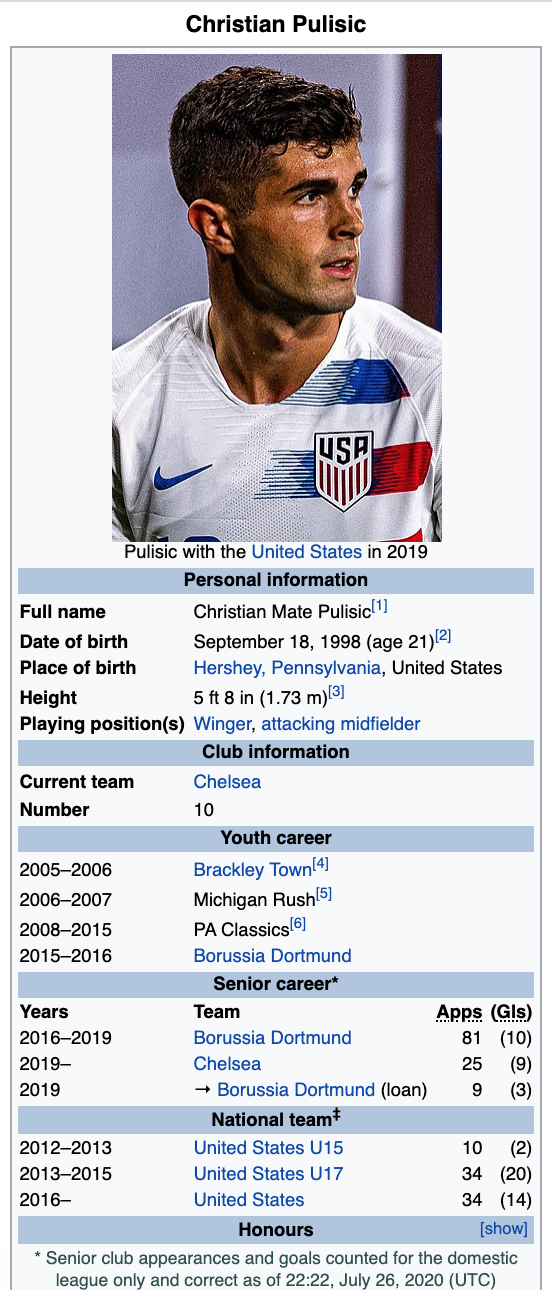
上記のコードを実行した後、スクリーンショットは次のようになります.
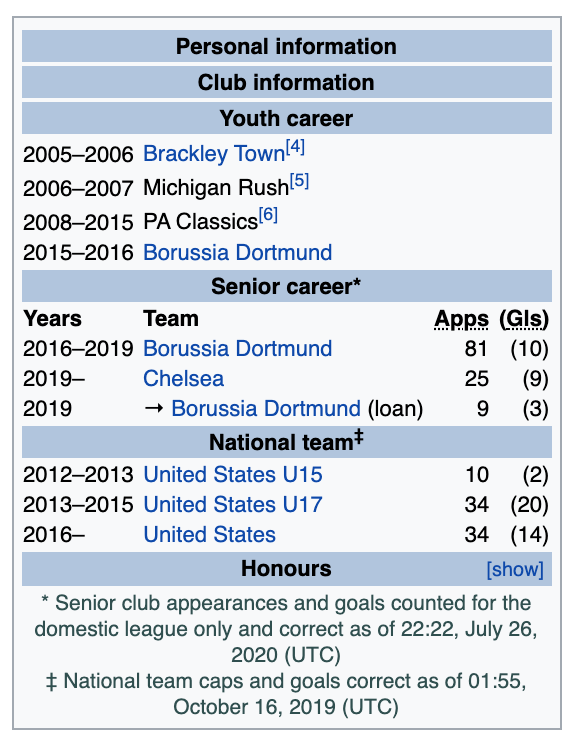
それは私が行っていた'トリビア'の側面だった.ユーザーがフットボール選手のチームを見ることができるが、他の情報から推測すること.
だから今、我々は必要なデータを持って、どのように実際にそれぞれの画像のスクリーンショットを取るのですか?おじさん!これは私の初めてこのツールを使用した.
操り人形ウェブサイトから.
Puppeteer is a Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol. Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium.
どうしたらいいですか.
ほとんどの場合は、ブラウザで手動で行うことができます人形を使用して行うことができます!以下にいくつかの例を示します.スクリーンショットとページのPDFを生成します. スパ(単一ページアプリケーション)をクロールし、プリレンダリングされたコンテンツを生成する(すなわち、“SSR”(サーバー側のレンダリング)). 自動フォームの提出、UIテスト、キーボード入力など. 最新の自動テスト環境を作成します.Chromeの最新バージョンでは、最新のJavaScriptとブラウザの機能を使用してテストを直接実行します. キャプチャーtimeline trace パフォーマンスの問題を診断するのを助けるあなたのサイトの. Chrome拡張をテストします. いくつかのブラウジングから、Pitpeteerテスト、自動化、およびウェブサイトからデータをこするための人気のツールです.私はページのスクリーンショットを取って、上記の最初の論点のためにそれを使いたかったです.
ドキュメントを読んで多くの時間を費やした後、これは私のスクリーンショットを取るために必要な基本的なコードだった-上記のコードは、Asyncの即時呼び出し関数です.行単位で、それはブラウザを起動し、入力したWebサイトに移動し、スクリーンショットを保存します.const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://example.com'); await page.screenshot({path: 'screenshot.png'}); await browser.close(); })();
これは全体のページのスクリーンショットを取るでしょう、そこで、私はフットボール選手の詳細で小さなインフォグラフィックボックスのスクリーンショットを探していました.
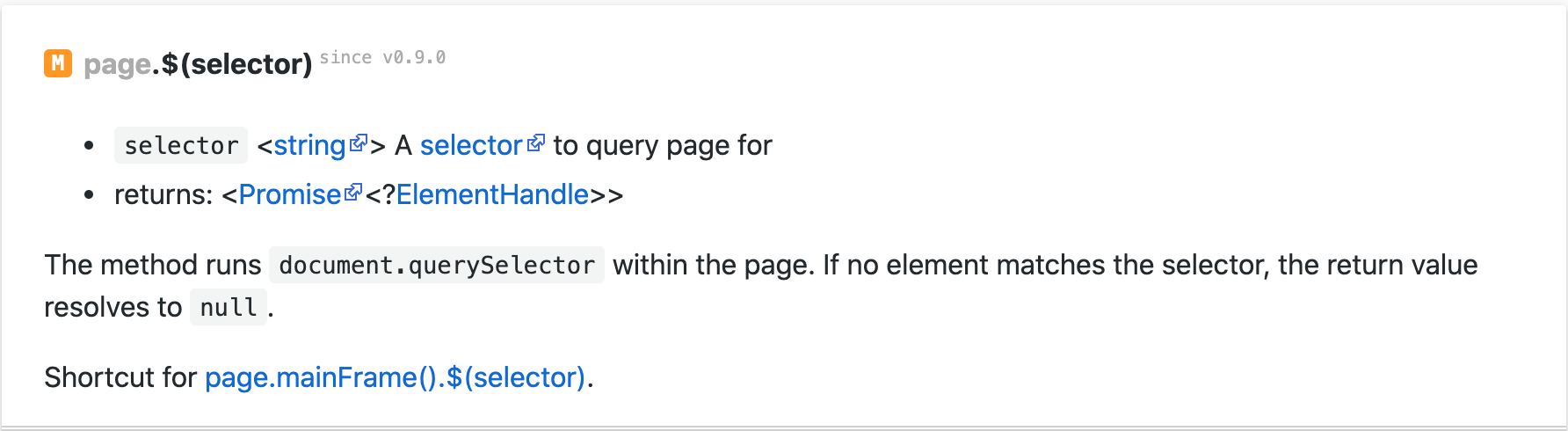
上記のメソッドを使って、スクリーンショットが欲しいページ要素を絞り込みました.tbody.要素を絞り込んだ後、スクリーンショットを取ることができます.したがって、それは我々の「答え」スクリーンショットであるので、すべてのフットボール選手の情報を持っています.const element = await page.$('tbody');我々は今、ほとんどのデータを削除した後、我々のインフォグラフィックボックスのスクリーンショットを取る必要があります.どうやったらこれができるの?await element.screenshot({ path: 'answer.png' });
ドキュメントのいくつかのより多くの精練とインターネットの検索のビットの後、我々は正しい方法を見つけます.
page.evaluate()
これにより、JavaScript ( QuerySelector (), ParentNode )を実行できます.先に述べたように、remove ()など).我々は必要なすべてのDOM要素を削除することができますし、スクリーンショットを取る.それで、我々は良いことをしています、我々は我々のスクリーンショットを持ちます!次のステップは、これらのアウトつぶやきに私たちのボットを取得することです.await page.evaluate(() => { try { if (document.contains(document.querySelector('.box-Tone'))) { document.querySelector('.box-Tone').remove(); } if (document.contains(document.querySelector('.box-Expand_language'))) { let languageBox = document.querySelectorAll('.box-Expand_language'); if (languageBox.length > 1) { let languageBoxes = Array.from(languageBox); languageBoxes.map((box) => box.remove()); } else { languageBox.remove(); } } let img = document.querySelector('.image'); let nickname = document.querySelector('.nickname'); let age = document.querySelector('.ForceAgeToShow'); let bplace = document.querySelector('.birthplace'); let role = document.querySelector('.role'); let org = document.querySelector('.org'); if (img) img.parentNode.remove(); if (nickname) nickname.parentNode.remove(); age.parentNode.parentNode.remove(); bplace.parentNode.nextSibling.remove(); bplace.parentNode.remove(); role.parentNode.remove(); if (org.parentNode.nextSibling) org.parentNode.nextSibling.remove(); if (org) org.parentNode.remove(); let birthname = document.querySelector('.nickname'); if (birthname) { birthname.parentNode.remove(); } let fullname = document.querySelector('.fn'); fullname.remove(); } catch (err) { console.log(err); } }); await element.screenshot({ path: 'player.png' }); await browser.close(); })();
我々が以前言及したように、Twitter APIクライアントは我々がメディアをさえずるのを聞かせました.
Twitドキュメントに戻ると、これはサンプルコードをつぶやきイメージのために提供されます我々は、ファイルを変更するだけで、ALTのテキストを変更し、ステータスを提供する必要があります(これは私たちのつぶやきのテキストとして表示されます).// // post a tweet with media // var b64content = fs.readFileSync('/path/to/img', { encoding: 'base64' }) // first we must post the media to Twitter T.post('media/upload', { media_data: b64content }, function (err, data, response) { // now we can assign alt text to the media, for use by screen readers and // other text-based presentations and interpreters var mediaIdStr = data.media_id_string var altText = "Small flowers in a planter on a sunny balcony, blossoming." var meta_params = { media_id: mediaIdStr, alt_text: { text: altText } } T.post('media/metadata/create', meta_params, function (err, data, response) { if (!err) { // now we can reference the media and post a tweet (media will attach to the tweet) var params = { status: 'loving life #nofilter', media_ids: [mediaIdStr] } T.post('statuses/update', params, function (err, data, response) { console.log(data) }) } }) })
関数としてラップしましたpostPlayer().私は答えを投稿するために再び同じコードを使用しました.function postPlayer() { let b64content = fs.readFileSync('./player.png', { encoding: 'base64' }); bot.post('media/upload', { media_data: b64content }, function ( err, data, response ) { let mediaIdStr = data.media_id_string; let altText = "Unknown footballer's statistics and information."; let meta_params = { media_id: mediaIdStr, alt_text: { text: altText } }; bot.post('media/metadata/create', meta_params, function ( err, data, response ) { if (!err) { let params = { status: 'Guess that player #footballtrivia #PremierLeague', media_ids: [mediaIdStr], }; bot.post('statuses/update', params, function (err, data, response) { console.log(data); }); } }); }); }次の課題は、ボットが同時にこれらをつぶやくことを保証することでした.我々は、ユーザーにいくつかの時間を見て、答えを投稿する前に推測するようにしたい.settimeout ()はつぶやきの遅延を与える良い方法です.function postAnswer() { let b64answer = fs.readFileSync('./answer.png', { encoding: 'base64' }); bot.post('media/upload', { media_data: b64answer }, function ( err, data, response ) { let mediaIdStr = data.media_id_string; let altText = 'Answer'; let meta_params = { media_id: mediaIdStr, alt_text: { text: altText } }; bot.post('media/metadata/create', meta_params, function ( err, data, response ) { if (!err) { let params = { status: `Today's answer #footballtrivia #PremierLeague`, media_ids: [mediaIdStr], }; bot.post('statuses/update', params, function (err, data, response) { console.log(data); }); } }); }); }大丈夫!我々のロボットは機能しています.次の最終的な挑戦はどのように実行し続けるかですか?我々はどこに1日に1回実行するプロジェクトをホストする場所を見つける必要があります.我々は手動で1日1回ローカルでプロジェクトを実行することができますが、それは実行可能なソリューションではありません.他のボットプロジェクトを見て、Herokuとグリッチは、あなたのTwitterボットプロジェクトをホストする人気のある場所でした.postPlayer(); setTimeout(postAnswer, 18000000); // in milliseconds, ~ 5 hours
Glitchは、ボットプロジェクトを構築したいなら、実際に良いスターターテンプレートを持っています
[グリッチによるtwitterbotプロジェクト]
あなたはTwitterのボットをオフに設定されるグリッチのURLを毎日訪問するcronジョブをスケジュールすることができます.私はいくつかの問題を抱えて作業し、別の解決策を試してみたかった.私はgithubアクションを見つけました.GitHub Actions makes it easy to automate all your software workflows, now with world-class CI/CD. Build, test, and deploy your code right from GitHub. Make code reviews, branch management, and issue triaging work the way you want.
- https://github.com/features/actions
また、私は把握するのにしばらくかかりました、しかし、私は結局それを走らせることができました.私の問題は私の環境変数に関するものでした.彼らはセキュリティ懸念のために私のGitHubリポジトリにプッシュされませんでした、そして、これは行動を起こして、走らせることに関する問題を引き起こしていました.
Githubアクションを開始するには、以下のフォルダをプロジェクトに追加します.
実際のガイドhttps://docs.github.com/en/actions/configuring-and-managing-workflows/configuring-a-workflow私はもともと自分が欲しかったアクションをスケジュールすることができました.スケジュールを実行することができます、あるいは、いつでも、コミットがあなたの倉庫にプッシュされます.私は予定された時間で毎日私のプロジェクトを実行することができました.走るmkdir .github/workflows touch .github/workflows/tweetbot.ymlnpm install, ENV変数にプラグを入れ、サーバを実行します.jsファイル.これが私の最初でした.YMLファイルは、あなたのインデントが正しいことを確認します.プロジェクトの完全なソースコードはここにあります.https://github.com/virenb/fbotname: Tweet on: schedule: - cron: "0 12 * * 0-6" jobs: build: runs-on: ubuntu-latest strategy: matrix: node-version: [12.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - name: set environment variables uses: allenevans/[email protected] with: consumer_key: ${{ secrets.CONSUMER_KEY }} consumer_secret: ${{ secrets.CONSUMER_SECRET }} access_token: ${{ secrets.ACCESS_TOKEN }} access_token_secret: ${{ secrets.ACCESS_TOKEN_SECRET }} - name: Start server run: npm run start
ボットはいくつかの信者を使用することができます興味を持って誰かと共有してください!
[プロジェクトは間違いなく進行中です.]
読んでくれてありがとう!資源
Node.js
Puppeteer
twit - Twitter API Client
Wikipedia
GitHub Actions
ありがとうTom Baranowicz & あなたのTwitterプロジェクトを共有するために、両方ともこれを構築する際のインスピレーションでした.
-
-
Reference
この問題について(フットボールを作る⚽) ノードとトリビアボット.JSと操り人形), 我々は、より多くの情報をここで見つけました https://dev.to/virenb/building-a-football-trivia-bot-with-node-js-puppeteer-432aテキストは自由に共有またはコピーできます。ただし、このドキュメントのURLは参考URLとして残しておいてください。
Collection and Share based on the CC Protocol