ウェブサイトの仕事を上手く仕事を提供します.
27839 ワード
こんにちは.今日は元気?私は、あなたに良い日があることを望みます:D ...
今日は、eコマースのウェブサイトを盗んだ後、私の経験を共有したいと思いますZomato . 私は現実世界のケースを実践するためにこのウェブサイトをscrapeします、私は仕事の上で仕事申し込みを見た後に、考えを得ました.
ジョブ説明
クライアントは、Zamatoウェブサイトの「メルボルン」オーストラリアの若干のカテゴリーから、ビジネス情報を傷つけるよう頼みました.カテゴリはカフェ、中国語、餃子、フランス語などです.すべてのデータをスプレッドシートに挿入する必要があります.
これはクライアントがscrapeしたいデータです.

このポストでは、私はこの仕事を終えるための最小限の要件を教えてください、あなたはそれを開発しようとすることができますか、または私の見ることができますGitHub .
何が必要か
主にHTTPリクエストを作成して、レスポンスを解析することは、ほとんどデータを掻き取ります.必要なライブラリは
インストール方法?
PIPコマンドを使用してライブラリをインストールします. それらの図書館を除いて、もちろん、私はscrapeしたいURLを必要とします.URLです.https://www.zomato.com/melbourne/restaurants/cafes . 主な領域→ https://www.zomato.com/
サブドメイン→ メルボルン/レストラン/カフェ.このサブドメインはクライアントが尋ねるものです、その最後の1つのカフェはカテゴリーです. 始めましょう
ステップ1.Pythonファイルを作成し、名前をメインにします.Py ,そしてファイルの上にライブラリをインポートします.
おい、私は、私がそうすることができます
ウェブサイト:“私はあなたのstatusChordコードを最初に表示させてください…それは403です.私はあなたがそれを望んでいるが、それを持っていることはできません知っている”
…を待つ.え?私の旅の間、私はステータスコードとして403を得たのはこれが初めてです.私が欲しいものは成功です.
私はインターネット上で解決策を捜そうとします、そして、幸運に、私はそれを見つけました.私のコードは
私がウェブサイトを要求しようとするとき、私の理解から、それは私が作った要求を「認識する」ことができません、しかし、私を入れません.それに何
それで私のコードは次のようになります.
ステップ3.今、ドアが開いていて、BeautifulSmokeを使ってデータを削る時間が来ました.それで、私はこのコードを書きます.
最後に、私がスープを印刷するとき、それはURLからHTMLコードを与えます. ステップ4.クライアントが望む値を抽出します.まず料理を見つけましょう.私はウェブサイトを開き、次に私のマウスを右クリックします.
それは何ですか.そのステップは、料理のテキストを含むHTMLタグを検索するために使用します.

GIFでは、料理を含むタグを検索することができます.タグ
使用
後にアンダースコアを追加することを忘れないでください
アバウト
ああ…私がこの記事を作成するとき、以下の絵として示されるページ

残りの値を抽出し続けましょう.基本的には料理の抽出と同じ.私はちょうどテキストの場所を見つけるために、タグ、およびクラス名を渡す必要があります.
組織のために
クライアントが指定したサンプルを見ると、場所とアドレスは同じ位置にあります.最初にテキストを取得します.

これがイメージYです
評価星の下には、クライアントのような値が場所にしたいです.それで、私はアドレスと同じ線から場所をつかむ必要はありません.今回は「一番大切なことは、クライアントが望んでいることを届けること」です.
場所をつかむ方法が見つかりました.すぐに、場所を含むタグを検索し、テキストを取得します.
所在地
私は正規表現について読んだことを覚えています.私はインターネット上でそれを検索しようとすると私は約
を、私はそれを得たが、別の混乱が表示されます、私はセパレータとして使用する必要があります?
私は再びYイメージを見ます、アドレスは前のコンマ→ 951マウンテンハイウェイ、ボロニア、メルボルン.最後に、それらをセパレータとして使用します.
アドレス
電話用:
理解
最終的なコードは次のようになります.
しかし、このポストでは、私は最初から私の旅を共有し、このポストを読むにはあまり長くはない.多分次のポストで、私は私の旅を共有し続けるでしょう.読書ありがとう.
p . sは質問をするのが恥ずかしいです、そして、あなたが何か間違った(コードまたは私の説明)を見つけるならば、どうか私に以下のコメントで知らせてください.前もって感謝します.
今日は、eコマースのウェブサイトを盗んだ後、私の経験を共有したいと思いますZomato . 私は現実世界のケースを実践するためにこのウェブサイトをscrapeします、私は仕事の上で仕事申し込みを見た後に、考えを得ました.
ジョブ説明
クライアントは、Zamatoウェブサイトの「メルボルン」オーストラリアの若干のカテゴリーから、ビジネス情報を傷つけるよう頼みました.カテゴリはカフェ、中国語、餃子、フランス語などです.すべてのデータをスプレッドシートに挿入する必要があります.
これはクライアントがscrapeしたいデータです.
このポストでは、私はこの仕事を終えるための最小限の要件を教えてください、あなたはそれを開発しようとすることができますか、または私の見ることができますGitHub .
何が必要か
主にHTTPリクエストを作成して、レスポンスを解析することは、ほとんどデータを掻き取ります.必要なライブラリは
request and beautifulsoup4 .インストール方法?
PIPコマンドを使用してライブラリをインストールします.
pip install requests pip install beautifulsoup4 ステップ1.Pythonファイルを作成し、名前をメインにします.Py ,そしてファイルの上にライブラリをインポートします.
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes')
print(res.status_code)
# 403
requests , これは私のアナロジーです.おい、私は、私がそうすることができます
get 品物"ウェブサイト:“私はあなたのstatusChordコードを最初に表示させてください…それは403です.私はあなたがそれを望んでいるが、それを持っていることはできません知っている”
…を待つ.え?私の旅の間、私はステータスコードとして403を得たのはこれが初めてです.私が欲しいものは成功です.
私はインターネット上で解決策を捜そうとします、そして、幸運に、私はそれを見つけました.私のコードは
User-Agent , これは、“サーバーとネットワークのピアは、アプリケーションを識別できるように”特徴的な文字列link もっと.私がウェブサイトを要求しようとするとき、私の理解から、それは私が作った要求を「認識する」ことができません、しかし、私を入れません.それに何
User-Agent です.Zomatoウェブサイトの観点からブラウザのような私のコード行為をしてください.それで私のコードは次のようになります.
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
print(res.status_code)
# 200
ステップ3.今、ドアが開いていて、BeautifulSmokeを使ってデータを削る時間が来ました.それで、私はこのコードを書きます.
soup = BeautifulSoup(res.text, 'html.parser')
print(soup)
# <!DOCTYPE html>
# <html lang="en" prefix="og: http://ogp.me/ns#">
# ...
# </html>
res.text → 上記の要求から(ステップ2)、HTMLをテキストとして取得したい.html.parser → Pythonが持っているパーサーライブラリです.パーサーについてtable . それは何ですか.そのステップは、料理のテキストを含むHTMLタグを検索するために使用します.
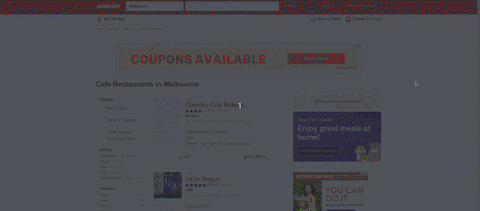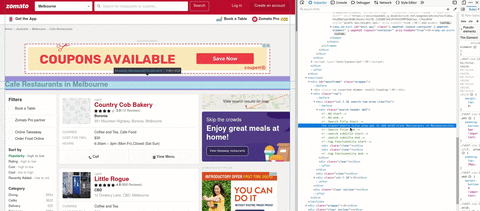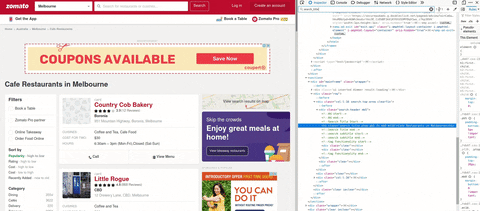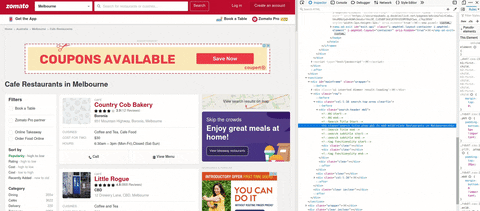
GIFでは、料理を含むタグを検索することができます.タグ
h1 そして、いくつかのクラス名があります.その検査要素の上に、検索HTMLを使用し、クラスをコピーします.使用
search_title つだけマッチしてmb0 私は8を得た.だから、このステップでは、私は使用しているsearch_title 料理を見つける.cuisine = soup.find('h1', class_='search_title').text
print(cuisine)
# Cafe Restaurants in Melbourne
find (詳細)link ). 括弧ではタグの名前ですh1 と属性class その後にsearch_title .後にアンダースコアを追加することを忘れないでください
class , あなたがそれを置かないならば、Pythonがあまりにもそのキーワードを持っているので、それはエラーを返します.アバウト
text 最後の部分では、目的のタグの間にテキストを取得することを意図しています.あなたがそれを書くならば、レスポンスはこれのように見えます.結果はタグが含まれます.# <h1 class="search_title ptop pb5 fn mb0 mt10">
# Cafe Restaurants in Melbourne
# </h1>
ああ…私がこの記事を作成するとき、以下の絵として示されるページ
残りの値を抽出し続けましょう.基本的には料理の抽出と同じ.私はちょうどテキストの場所を見つけるために、タグ、およびクラス名を渡す必要があります.
組織のために
organisation = soup.find('a', class_='result-title').text
print(organisation)
# Country Cob Bakery
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
print(asso_cuisine)
# Coffee and Tea, Cafe Food
クライアントが指定したサンプルを見ると、場所とアドレスは同じ位置にあります.最初にテキストを取得します.
test = soup.find('div', class_='search-result-address').text
print(test)
# 951 Mountain Highway, Boronia, Melbourne
これがイメージYです
評価星の下には、クライアントのような値が場所にしたいです.それで、私はアドレスと同じ線から場所をつかむ必要はありません.今回は「一番大切なことは、クライアントが望んでいることを届けること」です.
場所をつかむ方法が見つかりました.すぐに、場所を含むタグを検索し、テキストを取得します.
所在地
location = soup.find('a', class_='search_result_subzone').text
print(location)
# Boronia
私は正規表現について読んだことを覚えています.私はインターネット上でそれを検索しようとすると私は約
split() . 最初は思ったsplit() 正規表現の一部ですが、そうではありません.split() は、文字列を一部分割するために使用され、リストとして返り値を返します.str.split([separator [, maxsplit]])
split は空白(スペース、改行など)をセパレータとして扱うlink .を、私はそれを得たが、別の混乱が表示されます、私はセパレータとして使用する必要があります?
私は再びYイメージを見ます、アドレスは前のコンマ→ 951マウンテンハイウェイ、ボロニア、メルボルン.最後に、それらをセパレータとして使用します.
アドレス
address = soup.find('div', class_='search-result-address').text
separator = f', {location}'
address = address.split(separator)
print(address)
# [' 951 Mountain Highway', ', Melbourne']
print(address[0])
# 951 Mountain Highway
電話用:
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
print(phone)
# 03 9720 2500
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(res.text, 'html.parser')
cuisine = soup.find('h1', class_='search_title').text
organisation = soup.find('a', class_='result-title').text
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
location = soup.find('a', class_='search_result_subzone').text
address = soup.find('div', class_='search-result-address').text
test = soup.find('div', class_='search-result-address').text
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
separator = f', {location}'
address = address.split(separator)
address = address[0]
import csv
# Create csv file
writer = csv.writer(open('./result.csv', 'w', newline='')) # method w -> write
headers = ['Cuisine', 'Assosiation Cuisine', 'Organisation', 'Address', 'Location', 'Phone']
writer.writerow(headers)
open() 関数は結果をオープンします.CSVは、残りの部分は、それはcsv.writer() . しかし、私はなぜ私の心がそれを集中できないかを知りませんopen() 関数です.ではなくcsv.writer() .理解
open() 関数.最初にcsvファイルの名前を書き、w このメソッドは、書き込みを表します.とnewline ドキュメントによると、どのように一般的な改行モードが動作するかを制御します.これは', ', '\n ',\\r ',\\r\n 'であるlink csv.writer ユーザのデータを区切られた文字列に変換するwriter.writerow() 同時に一つの行を書く.→ link # Add the value to csv file
writer = csv.writer(open('./result.csv', 'a', newline='', encoding='utf-8')) # method a -> append
data = [cuisine, asso_cuisine, organisation, address, location, phone]
writer.writerow(data)
a その中でa appendを表します.参照→ link 最終的なコードは次のようになります.
import csv
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(res.text, 'html.parser')
cuisine = soup.find('h1', class_='search_title').text
organisation = soup.find('a', class_='result-title').text
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
location = soup.find('a', class_='search_result_subzone').text
address = soup.find('div', class_='search-result-address').text
test = soup.find('div', class_='search-result-address').text
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
separator = f', {location}'
address = address.split(separator)
address = address[0]
writer = csv.writer(open('./result.csv', 'w', newline='')) # method w -> write
headers = ['Cuisine', 'Assosiation Cuisine', 'Organisation', 'Address', 'Location', 'Phone']
writer.writerow(headers)
writer = csv.writer(open('./result.csv', 'a', newline='', encoding='utf-8')) # method a -> append
data = [cuisine, asso_cuisine, organisation, address, location, phone]
writer.writerow(data)
しかし、このポストでは、私は最初から私の旅を共有し、このポストを読むにはあまり長くはない.多分次のポストで、私は私の旅を共有し続けるでしょう.読書ありがとう.
p . sは質問をするのが恥ずかしいです、そして、あなたが何か間違った(コードまたは私の説明)を見つけるならば、どうか私に以下のコメントで知らせてください.前もって感謝します.
Reference
この問題について(ウェブサイトの仕事を上手く仕事を提供します.), 我々は、より多くの情報をここで見つけました https://dev.to/ilhamday/my-first-journey-scrape-website-based-on-upwork-job-offer-1-od2テキストは自由に共有またはコピーできます。ただし、このドキュメントのURLは参考URLとして残しておいてください。
Collection and Share based on the CC Protocol