ダウンロードしてGoogleのイメージをダウンロードしてPython
33137 ワード
目次:intro , imports , what will be scraped , process , code , links , outro .
このブログのポストは、GoogleのWebスクレーピングシリーズの継続です.ここでは、どのようにGoogleを使用して画像をスクラップを参照してください
前提条件:基礎知識
推奨検索結果

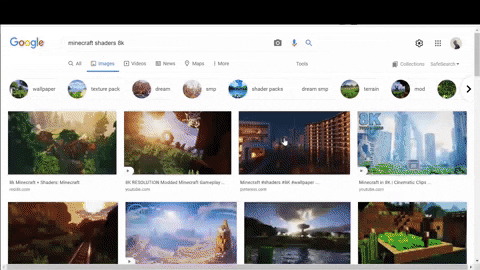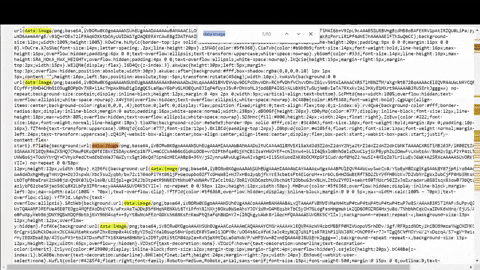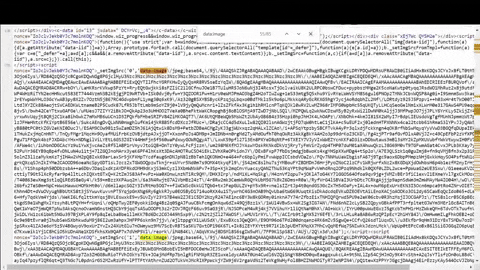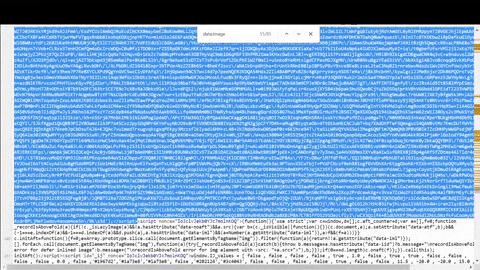
イメージ結果

まず、必要なデータ、名前、リンク、提案された検索結果のためのチップを使用してコンテナを選択します.CSS selector reference .

第二に、デコードされたサムネイルのURLは、提案された検索結果の場所を探してください.

上記のGIFにコピーしました
なぜ、私はちょうど解析することができませんか
論理は以下の通りでした.
どこにいるのか
テキストの大きな塊からテキストの特定のチャックを分割してより簡単にするためにより小さいものに分割する
クリエイトア
正規表現をテストするにはregex101 .
画像を保存
画像を保存するには
両方の関数のコードの開始

注:私はコーディングの瞬間に直感的に感じたプロセスを予定していた.より良い

SerPapiは無料のプランで有料APIです.
違いは、構造化を繰り返すことです

Code in the online IDE • Google Images API
何か質問や何かが正しく動作していない場合や他の何かを書くには、コメントのセクションやTwitter経由でコメントをドロップすること自由に感じなさい.
あなた
Dimitryと残りのserpapiチーム.
イントロ
このブログのポストは、GoogleのWebスクレーピングシリーズの継続です.ここでは、どのようにGoogleを使用して画像をスクラップを参照してください
beautifulsoup , requests , lxml ライブラリ.別のAPIソリューションを示します.前提条件:基礎知識
beautifulsoup , requests , lxml と正規表現.輸入
import requests, lxml, re, json, urllib.request
from bs4 import BeautifulSoup
スクラップ
推奨検索結果
イメージ結果
プロセス
まず、必要なデータ、名前、リンク、提案された検索結果のためのチップを使用してコンテナを選択します.CSS selector reference .
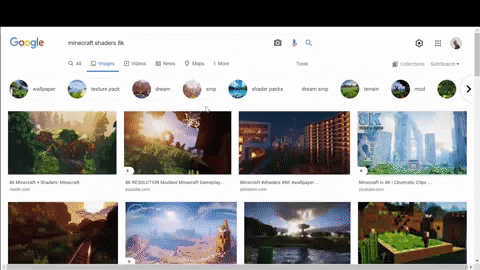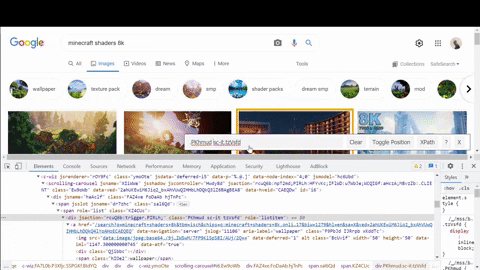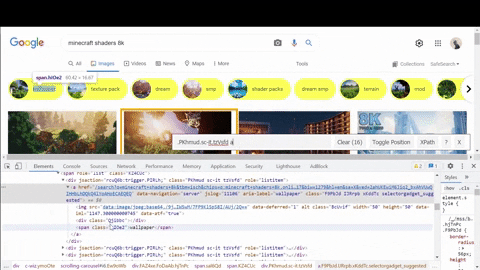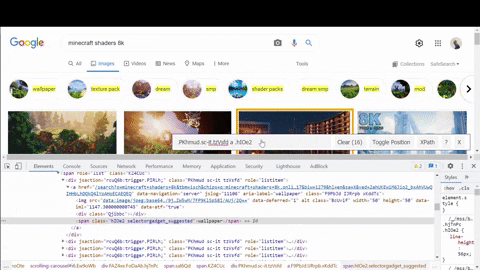
第二に、デコードされたサムネイルのURLは、提案された検索結果の場所を探してください.
上記のGIFにコピーしました
data:image 一部src Chromeでチェックする属性find bar ( Ctrl + F )私が探していたものが<script> タグ.なぜ、私はちょうど解析することができませんか
src 属性img エレメント?If you parse
<img>withsrcattribute, you'll get an 1x1 placeholder instead of actual thumbnail.
論理は以下の通りでした.
どこにいるのか
<script> タグをデコードサムネイルURLが位置していた.テキストの大きな塊からテキストの特定のチャックを分割してより簡単にするためにより小さいものに分割する
regex 抽出.クリエイトア
regex すべてのURLにマッチするパターン.同様の処理を元の解像度画像をサムネイルで抽出するために適用した.画像を保存
画像を保存するには
urllib.request.urlretrieve(url, filename) ( more in-depth )# often times it will throw 404 error, so to avoid it we need to pass user-agent
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(original_size_img, f'LOCAL_FOLDER_NAME/YOUR_IMAGE_NAME.jpg')
コード
両方の関数のコードの開始
import requests, lxml, re, datetime
from bs4 import BeautifulSoup
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "minecraft shaders 8k photo",
"tbm": "isch",
"ijn": "0",
}
html = requests.get("https://www.google.com/search", params=params, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
def get_suggested_search_data():
for suggested_search in soup.select('.PKhmud.sc-it.tzVsfd'):
suggested_search_name = suggested_search.select_one('.hIOe2').text
suggested_search_link = f"https://www.google.com{suggested_search.a['href']}"
# https://regex101.com/r/y51ZoC/1
suggested_search_chips = ''.join(re.findall(r'=isch&chips=(.*?)&hl=en-US', suggested_search_link))
print(f"{suggested_search_name}\n{suggested_search_link}\n{suggested_search_chips}\n")
# this steps could be refactored to a more compact
all_script_tags = soup.select('script')
# https://regex101.com/r/48UZhY/6
matched_images_data = ''.join(re.findall(r"AF_initDataCallback\(({key: 'ds:1'.*?)\);</script>", str(all_script_tags)))
# https://kodlogs.com/34776/json-decoder-jsondecodeerror-expecting-property-name-enclosed-in-double-quotes
# if you try to json.loads() without json.dumps() it will throw an error:
# "Expecting property name enclosed in double quotes"
matched_images_data_fix = json.dumps(matched_images_data)
matched_images_data_json = json.loads(matched_images_data_fix)
# search for only suggested search thumbnails related
# https://regex101.com/r/ITluak/2
suggested_search_thumbnails_data = ','.join(re.findall(r'{key(.*?)\[null,\"Size\"', matched_images_data_json))
# https://regex101.com/r/MyNLUk/1
suggested_search_thumbnail_links_not_fixed = re.findall(r'\"(https:\/\/encrypted.*?)\"', suggested_search_thumbnails_data)
print('Suggested Search Thumbnails:') # in order
for suggested_search_fixed_thumbnail in suggested_search_thumbnail_links_not_fixed:
# https://stackoverflow.com/a/4004439/15164646 comment by Frédéric Hamidi
suggested_search_thumbnail = bytes(suggested_search_fixed_thumbnail, 'ascii').decode('unicode-escape')
print(suggested_search_thumbnail)
get_suggested_search_data()
def get_images_data():
print('\nGoogle Images Metadata:')
for google_image in soup.select('.isv-r.PNCib.MSM1fd.BUooTd'):
title = google_image.select_one('.VFACy.kGQAp.sMi44c.lNHeqe.WGvvNb')['title']
source = google_image.select_one('.fxgdke').text
link = google_image.select_one('.VFACy.kGQAp.sMi44c.lNHeqe.WGvvNb')['href']
print(f'{title}\n{source}\n{link}\n')
# this steps could be refactored to a more compact
all_script_tags = soup.select('script')
# # https://regex101.com/r/48UZhY/4
matched_images_data = ''.join(re.findall(r"AF_initDataCallback\(([^<]+)\);", str(all_script_tags)))
# https://kodlogs.com/34776/json-decoder-jsondecodeerror-expecting-property-name-enclosed-in-double-quotes
# if you try to json.loads() without json.dumps it will throw an error:
# "Expecting property name enclosed in double quotes"
matched_images_data_fix = json.dumps(matched_images_data)
matched_images_data_json = json.loads(matched_images_data_fix)
# https://regex101.com/r/pdZOnW/3
matched_google_image_data = re.findall(r'\[\"GRID_STATE0\",null,\[\[1,\[0,\".*?\",(.*),\"All\",', matched_images_data_json)
# https://regex101.com/r/NnRg27/1
matched_google_images_thumbnails = ', '.join(
re.findall(r'\[\"(https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)\",\d+,\d+\]',
str(matched_google_image_data))).split(', ')
print('Google Image Thumbnails:') # in order
for fixed_google_image_thumbnail in matched_google_images_thumbnails:
# https://stackoverflow.com/a/4004439/15164646 comment by Frédéric Hamidi
google_image_thumbnail_not_fixed = bytes(fixed_google_image_thumbnail, 'ascii').decode('unicode-escape')
# after first decoding, Unicode characters are still present. After the second iteration, they were decoded.
google_image_thumbnail = bytes(google_image_thumbnail_not_fixed, 'ascii').decode('unicode-escape')
print(google_image_thumbnail)
# removing previously matched thumbnails for easier full resolution image matches.
removed_matched_google_images_thumbnails = re.sub(
r'\[\"(https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)\",\d+,\d+\]', '', str(matched_google_image_data))
# https://regex101.com/r/fXjfb1/4
# https://stackoverflow.com/a/19821774/15164646
matched_google_full_resolution_images = re.findall(r"(?:'|,),\[\"(https:|http.*?)\",\d+,\d+\]",
removed_matched_google_images_thumbnails)
print('\nFull Resolution Images:') # in order
for index, fixed_full_res_image in enumerate(matched_google_full_resolution_images):
# https://stackoverflow.com/a/4004439/15164646 comment by Frédéric Hamidi
original_size_img_not_fixed = bytes(fixed_full_res_image, 'ascii').decode('unicode-escape')
original_size_img = bytes(original_size_img_not_fixed, 'ascii').decode('unicode-escape')
print(original_size_img)
# ------------------------------------------------
# Download original images
# print(f'Downloading {index} image...')
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(original_size_img, f'YOUR_LOCALFOLDER/YOUR_FILE_NAME.jpg')
get_google_images_data()
regex オリジナルの解像度画像を展開するパターン1. \[\d+,\[\d+,\"\w+\",,\[\"(https:|http.*?)\",\d+,\d+\]
2. \[\"(https:|http.*?)\",\d+,\d+\]
3. ['|,,]\[\"(https:|http.*?)\",\d+,\d+\]
4. (?:'|,),\[\"(https|http.*?)\",\d+,\d+\] # final
-------------------------------------------------
Google Suggested Search Results
-------------------------------------------------
texture pack
https://www.google.com/search?q=minecraft+shaders+8k+photo&tbm=isch&chips=q:minecraft+shaders+8k+photo,online_chips:texture+pack:5UdWXA5mkNo%3D&hl=en-US&sa=X&ved=2ahUKEwiRy8vcgPnxAhUpu6QKHV9FCLsQ4lYoAHoECAEQEA
q:minecraft+shaders+8k+photo,online_chips:texture+pack:5UdWXA5mkNo%3D
...
Suggested Search Thumbnails:
https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQPsrr--O2yuSyFg-Al3DN0MyhhuO2RcktFCEFiuzs1RoK4oZvS&usqp=CAU
...
-------------------------------------------------
Google Images Results
-------------------------------------------------
8K RESOLUTION Modded Minecraft Gameplay With Ultra Shaders (Yes Really) - YouTube
youtube.com
https://www.youtube.com/watch?v=_mR0JBLXRLY
...
Google Image Thumbnails:
https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR6RRuk2k_wMIMt4hhNAatPgmfrDWvAsXrKC90LeBn4GDoySeBQPruapu7ADCSVyORtU48&usqp=CAU
...
Google Full Resolution Images:
https://i.ytimg.com/vi/_mR0JBLXRLY/maxresdefault.jpg

注:私はコーディングの瞬間に直感的に感じたプロセスを予定していた.より良い
regex コードを分割するコードのパターンと行の数が少ないregex , しかし、速度に関して、上記のGIFは、すべてが0 : 00 : 00 : 975229マイクロ秒でかなり速く起こると示します. GoogleイメージAPIの使用
SerPapiは無料のプランで有料APIです.
違いは、構造化を繰り返すことです
JSON ここでデコードされたサムネイルとその元の解像度はかなり素晴らしい場所を考え出す.
import os, urllib.request, json # json for pretty output
from serpapi import GoogleSearch
def get_google_images():
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google",
"q": "pexels cat",
"tbm": "isch"
}
search = GoogleSearch(params)
results = search.get_dict()
# print(json.dumps(results['suggested_searches'], indent=2, ensure_ascii=False))
print(json.dumps(results['images_results'], indent=2, ensure_ascii=False))
# -----------------------
# Downloading images
for index, image in enumerate(results['images_results']):
print(f'Downloading {index} image...')
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(image['original'], f'SerpApi_Images/original_size_img_{index}.jpg')
get_google_images()
---------------------
'''
Suggested search results:
[
{
"name": "wallpaper",
"link": "https://www.google.com/search?q=minecraft+shaders+8k+photo&tbm=isch&chips=q:minecraft+shaders+8k+photo,online_chips:wallpaper:M78_F4UxoJw%3D&hl=en-US&sa=X&ved=2ahUKEwibusKPuvjxAhWFEt8KHbN0CBUQ4lYoAHoECAEQEQ",
"chips": "q:minecraft+shaders+8k+photo,online_chips:wallpaper:M78_F4UxoJw%3D",
"serpapi_link": "https://serpapi.com/search.json?chips=q%3Aminecraft%2Bshaders%2B8k%2Bphoto%2Conline_chips%3Awallpaper%3AM78_F4UxoJw%253D&device=desktop&engine=google&google_domain=google.com&q=minecraft+shaders+8k+photo&tbm=isch",
"thumbnail": "https://serpapi.com/searches/60fa52ca477c0ec3f75f0d3b/images/3868309500692ce40237282387fb16587c67c8a9bb635eefe35216c182003a4d.jpeg"
}
...
]
---------------------
Image results:
[
{
"position": 1,
"thumbnail": "https://serpapi.com/searches/60fa52ca477c0ec3f75f0d3b/images/07dc65d29a3e1094e9c1551efe12324ee8387d268cf2eec92bf0eaed1550eecb.jpeg",
"source": "reddit.com",
"title": "8k Minecraft + Shaders: Minecraft",
"link": "https://www.reddit.com/r/Minecraft/comments/6iamxa/8k_minecraft_shaders/",
"original": "https://external-preview.redd.it/mAQWN2kUYgFS3fgm6LfYo37AY7i2e_YY8d83_1jTeys.jpg?auto=webp&s=b2bad0e23cbd83426b06e6a547ef32ebbc08e2d2"
}
...
]
'''
リンク
Code in the online IDE • Google Images API
アウトロ
何か質問や何かが正しく動作していない場合や他の何かを書くには、コメントのセクションやTwitter経由でコメントをドロップすること自由に感じなさい.
あなた
Dimitryと残りのserpapiチーム.
Reference
この問題について(ダウンロードしてGoogleのイメージをダウンロードしてPython), 我々は、より多くの情報をここで見つけました https://dev.to/dmitryzub/scrape-google-images-with-python-1ee2テキストは自由に共有またはコピーできます。ただし、このドキュメントのURLは参考URLとして残しておいてください。
Collection and Share based on the CC Protocol