紺碧のコスチュDB
スキーマのないデータベースMongo DBに似て私たちのデザインモデル、ストア、クエリデータを簡単かつ迅速に役立ちます.しかし、パフォーマンス、スケーラビリティ、コストなどに大きな影響を与えるアプリケーションの正しいスキーマデザインを理解し、設計し、作成することはとても重要です.
以下は、我々がMongo DBで我々のデータモデルを始める前に考慮する必要のある主要な要因です.は、スキーマのないMongo/AzureコスモスDB に正規化/関係データベース間の違いを理解しますは、我々のアプリケーションが読むか、重い を書くことですスキーマレスデータベースにおけるデータのモデル化方法 私たちがデータを埋め込む必要があるシナリオとどのシナリオを我々がデータを参照する必要があるか.
データモデルパターンの埋め込み
開発者/アーキテクトとして、スキーマレスデータベースで作業を開始すると、リレーショナルまたは正規化データベースに似たスキーマをデザインする傾向があります.我々は伝統的にSQL規格化されたデータベースで設計するように、複数のテーブルにデータを設計したいと思いますが、我々はMongo DBの大きな利点を見逃すでしょう.
したがって、従来の正規化/リレーショナルデータベースとスキーマレスデータベース間の違いを理解する方が良いです.
たとえば、リレーショナルスキーマデザインでは、開発者はクエリに依存しないスキーマをデザインします.各レコードに冗長データを格納するのを避けるために複数のエンティティにデータを正規化し、関連するエンティティのデータを参照します.
以下の例では、リレーショナルデータベース内のデータをどのようにモデル化するかを示します.
関係データベースにおける順序データスキーマ設計

順序、項目の詳細、連絡先の詳細などを問い合わせるには、他のテーブルに結合してデータを取得する必要があります.
同様に、単一の注文項目の詳細を更新するには、複数のテーブルを更新する必要があります.
mongo/azure cosmos dbで同じ順序データモデルをどのように設計できるかを見てみましょう.
また、任意のフィールドまたはサブオブジェクト/配列形式を完全にいつでも変更する柔軟性があります.
現在、我々は一つの埋め込まれた文書に対する1つの質問/読み出し操作で完全な順序詳細を取り戻すことができます.
同様に、アイテムの詳細と配送情報の順序を更新するには、単一の注文ドキュメントに対して単一の更新/書き込み操作で行うことができます.
一般に、それは常にembedのために行くことをお勧めします.いくつかの特定のケースを除いて、参照のために行く必要があります.埋め込みはまた、クエリの読み込みパフォーマンスを向上させます.

参照データモデルパターン
埋め込むためのデータが少ない限り、スキーマデザインの埋め込みには良い.つの1つと1つのいくつかの関係エンティティについては、埋め込みデータモデルパターンが最適です.
しかし、私たちが埋め込むのにあまりに多くのデータを持っているならば、子供文書が制限を超えて成長することができる1つの多くの関係実体のために、または、データが頻繁に変わるかもしれない所で、データモデルパターンを参照するほうがよいです.
例えば、図書館の商品カタログには、日常的に変化し続ける本項目の数が“n”であり、定期的に成長を体験できる.
カタログ
書籍
頻繁なデータ更新のためのもう一つの鍵となる例は天候、証券取引所などです.これらの例では、埋め込みデータモデルパターンは良い選択ではないかもしれません.

一言で言えば、データを埋め込むか、SQLでデータを正規化することに類似したドキュメントを参照することによって、我々はMongo DBで我々のデータをモデル化することができる異なった方法があります.
これらの2つのデータモデルパターンを使用することによって、効率的でスケーラブルで強力なクエリを、アプリケーションに対して完全に非常に有用であり、インパクトのあるドキュメントにすることができます.
私の学習と経験に基づいて、私は埋め込みデザインとリファレンスデザインについて少し触れました.これらのデータモデルのパターンとベストプラクティスについての詳細を知るために、すべての異なる1つ、1つ、いくつかの、多くの多くの多くの関係の例について読んで学ぶことがたくさんあります.
詳細な学習のための公式モンゴDBとAzureコスモスDBのドキュメントをチェックアウトしてください.

この投稿を読んでくれてありがとう!
私は、この記事が有益で有益であることを望みます.それがあるならば、この記事を好きで、共有してください.関連するヒントや記事については、私に従ってください.
ハッピーラーニング!
以下は、我々がMongo DBで我々のデータモデルを始める前に考慮する必要のある主要な要因です.
データモデルパターンの埋め込み
開発者/アーキテクトとして、スキーマレスデータベースで作業を開始すると、リレーショナルまたは正規化データベースに似たスキーマをデザインする傾向があります.我々は伝統的にSQL規格化されたデータベースで設計するように、複数のテーブルにデータを設計したいと思いますが、我々はMongo DBの大きな利点を見逃すでしょう.
したがって、従来の正規化/リレーショナルデータベースとスキーマレスデータベース間の違いを理解する方が良いです.
たとえば、リレーショナルスキーマデザインでは、開発者はクエリに依存しないスキーマをデザインします.各レコードに冗長データを格納するのを避けるために複数のエンティティにデータを正規化し、関連するエンティティのデータを参照します.
以下の例では、リレーショナルデータベース内のデータをどのようにモデル化するかを示します.
関係データベースにおける順序データスキーマ設計
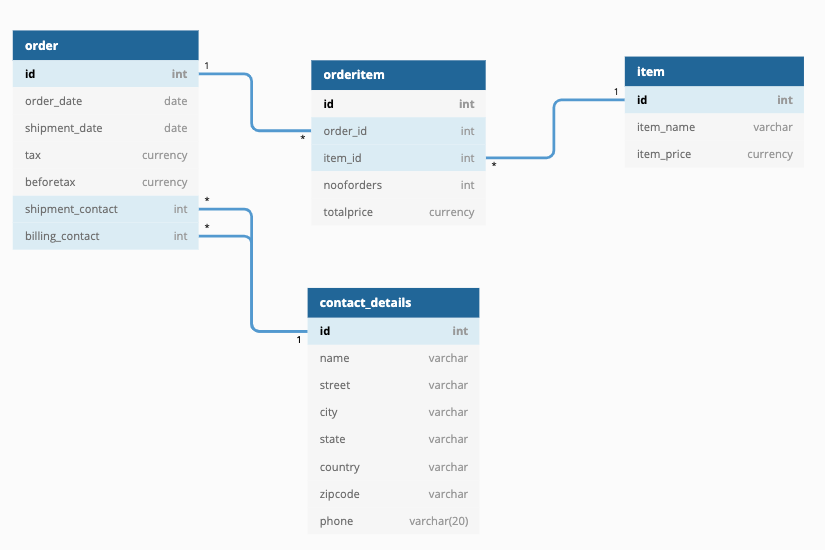
順序、項目の詳細、連絡先の詳細などを問い合わせるには、他のテーブルに結合してデータを取得する必要があります.
同様に、単一の注文項目の詳細を更新するには、複数のテーブルを更新する必要があります.
mongo/azure cosmos dbで同じ順序データモデルをどのように設計できるかを見てみましょう.
{
“id”: “1”,
“orderdate”: “02/08/2021”,
“tax” : “8”,
“subtotalbeforetax”: “69”,
“shipmentdate”: “03/08/2021”,
“orderitems”: [
{
“itemname”: “item1”,
“quantity”: “2”,
“itemprice”: “12”,
“totalprice”:”24"
},
{ “itemname”: “item2”,
“quantity”: “3”,
“itemprice”: “15”,
“totalprice”: “45”
}
],
“shippingcontact”: [
{
“name”: “<<person1>>”,
“street”: “<<street1>>”,
“city”: “<<city1>>”,
“state”: “<<state1>>”,
“country”: “<<country1>>”,
“zipcode”: “<<zipcode1>>”,
“phone”: “<<street1>>”
},
]
“billingcontact”: [
{
“name”: “<<person1>>”,
“street”: “<<street1>>”,
“city”: “<<city1>>”,
“state”: “<<state1>>”,
“country”: “<<country1>>”,
“zipcode”: “<<zipcode1>>”,
“phone”: “<<street1>>”
},
]
}
また、任意のフィールドまたはサブオブジェクト/配列形式を完全にいつでも変更する柔軟性があります.
現在、我々は一つの埋め込まれた文書に対する1つの質問/読み出し操作で完全な順序詳細を取り戻すことができます.
同様に、アイテムの詳細と配送情報の順序を更新するには、単一の注文ドキュメントに対して単一の更新/書き込み操作で行うことができます.
一般に、それは常にembedのために行くことをお勧めします.いくつかの特定のケースを除いて、参照のために行く必要があります.埋め込みはまた、クエリの読み込みパフォーマンスを向上させます.

参照データモデルパターン
埋め込むためのデータが少ない限り、スキーマデザインの埋め込みには良い.つの1つと1つのいくつかの関係エンティティについては、埋め込みデータモデルパターンが最適です.
しかし、私たちが埋め込むのにあまりに多くのデータを持っているならば、子供文書が制限を超えて成長することができる1つの多くの関係実体のために、または、データが頻繁に変わるかもしれない所で、データモデルパターンを参照するほうがよいです.
例えば、図書館の商品カタログには、日常的に変化し続ける本項目の数が“n”であり、定期的に成長を体験できる.
カタログ
“Product_Catolog” :
{
“id”: “1”,
“libraryname”: “<<libraryname>>”,
“product_catalog_no”: “1234”,
“books”: [“BookId(‘1111’)”, “BookId(‘2222’)”, “BookId(‘3333’)”]
}
書籍
“books” :[
{
“_id” : “Id(‘1111’)”,
“title” : “Book 1111”,
“author” : “Author 1111”,
“qty”: “10”,
“price”:” 24.99"
}
{
“_id” : “Id(‘2222’)”,
“title” : “Book 2222”,
“author” : “Author 2222”,
“qty”: “15”,
“price”:” 30.99"
}
{
“_id” : “Id(‘3333’)”,
“title” : “Book 3333”,
“author” : “Author 3333”,
“qty”: “20”,
“price”:” 14.99"
}
]
頻繁なデータ更新のためのもう一つの鍵となる例は天候、証券取引所などです.これらの例では、埋め込みデータモデルパターンは良い選択ではないかもしれません.

一言で言えば、データを埋め込むか、SQLでデータを正規化することに類似したドキュメントを参照することによって、我々はMongo DBで我々のデータをモデル化することができる異なった方法があります.
これらの2つのデータモデルパターンを使用することによって、効率的でスケーラブルで強力なクエリを、アプリケーションに対して完全に非常に有用であり、インパクトのあるドキュメントにすることができます.
私の学習と経験に基づいて、私は埋め込みデザインとリファレンスデザインについて少し触れました.これらのデータモデルのパターンとベストプラクティスについての詳細を知るために、すべての異なる1つ、1つ、いくつかの、多くの多くの多くの関係の例について読んで学ぶことがたくさんあります.
詳細な学習のための公式モンゴDBとAzureコスモスDBのドキュメントをチェックアウトしてください.

この投稿を読んでくれてありがとう!
私は、この記事が有益で有益であることを望みます.それがあるならば、この記事を好きで、共有してください.関連するヒントや記事については、私に従ってください.
ハッピーラーニング!
Reference
この問題について(紺碧のコスチュDB), 我々は、より多くの情報をここで見つけました https://dev.to/geetcloud/azure-cosmos-db-mongo-db-embedding-vs-reference-81pテキストは自由に共有またはコピーできます。ただし、このドキュメントのURLは参考URLとして残しておいてください。
Collection and Share based on the CC Protocol