Azure で ML Ops をやってみる ~実践編~
目次
- はじめに
- 今回利用するサービス
- 今回利用するGitHub リポジトリ
- 実践編
- 最後に
はじめに
この記事は株式会社ナレッジコミュニケーションが運営する
クラウドAI by ナレコム Advent Calendar 2021 の12日目にあたる記事になります。
こんにちは!
前回のパートで、機械学習モデルを運用する上での課題と、MLOps の概念について触れました。
こちらの記事では、どのように Azure サービスを用いて MLOps を実践するのか、手順などをまとめていきたいと思います。
Azure で MLOps ライフサイクルを実践するためのベストプラクティス
下記の図の5点が、Azure サービスで優れた MLOps 基盤を作るためのベストプラクティスを示した図になります。

-
再利用できるパイプラインでモデルを作成する
- モデリングに利用するデータセットの選択、各種パラメータの設定などもひとまとめにして、モデル作成のプロセスをパイプライン化します。
-
モデル登録の自動化
- イベント駆動型で本番稼働するモデルを変えられるように、メタ情報も含めてモデルのバージョン管理を行います。
-
監査証左の自動化
- テストコードも含めてパイプラインで一元管理します。
-
モニタリングをともなうデプロイ
- 機械学習モデルの再トレーニングのタイミングを見極めるために重要になっていきます。
-
データドリフトの検知
- ドリフトに周期性がみられる場合にはスケジュールベースでのリモデルも考えられますが、基本的にはドリフトの状況を見て再トレーニングを行います。
今回利用する GitHub リポジトリ
今回利用する Github リポジトリは以下の URL です。
実践編
今回実装するアーキテクチャ図
今回実装する範囲は、以下のアーキテクチャ図の赤枠部分になります。
次項から、実装に移りたいと思います。

Azure Pipelineの設定
Azure Pipeline設定
Azure Machine Learningとインフラ環境を構築していきます。
以下のアーキテクチャ図の赤枠部分を構成していきます。

今回のメイン作業スペース、Azure DevOps を開きます。

Azure DevOps 左サイドメニューから Pipelines をクリックします。
今回は大きく分けて3つのパイプラインを構築していきます。

1つ目のパイプライン AML-Iac
Azure Machine Learningを含めた インフラ環境を構築するためのパイプライン
2つ目のパイプライン Model Train Register CI
機械学習モデルの作成・及び登録を行うようなパイプライン
3つ目のパイプライン Model Deploy CD
Container Instance 、AKS にデプロイするような CD のパイプライン
フォークしたリポジトリ
GitHubからリポジトリをフォークします。
フォークしたリポジトリはAzure DevOpsのReposから確認できます。

各パイプラインは、例えばモデルの作成を開くと、
diabetes_regression-ci.yml
モデル実行時に利用するような python のスクリプト、
下の階層で利用するような YAML が定義されています。

変数定義
次に、パイプライン上の変数を設定して行きます。

Pipelines > Library と進みまして、変数のグループを作成します。

下記画面から、変数名と各種変数を設定します。

今回追加した変数は9個です。
-
ACI_DEPLOYMENT_NAME / AKS_DEPLOYMENT_NAME
- これらはそれぞれ ACI と AKS のデプロイの名称になっています。
-
AKS_COMPUTER_NAME
- 推論クラスターの名称で、こちらは Azure Machine Learning側で設定します。
-
Azure_RM_SVC_CONNECTION
- こちらは、Azure パイプラインが Azure Resource Manager を介して、Azure Machine Learning ワークスペースと関連リソースを作成するための接続線です。
-
BASE_NAME
- リソースに名前をつけるためのプレフィックスになっています。
-
LOCATION
- Azure Devops のリソースロケーションを設定しています。
-
RESOURCE_GROUP
- 新規作成するAzure Machine Learning のリソースグループ名を定義しています。
-
WORKSPACE_NAME
- 作成するAzure Machine Learning のワークスペース名を定義しています。
-
WORKSPACE_SVC_CONNECTION
- こちらは、Azure パイプラインが Azure Machine Learning ワークスペースとの接続を行うためのコネクションです。
変数の追加が終わりましたら、次にコネクションを作成していきます。

ワークスペース用 コネクションの作成
Azure DevOpsからAzure Machine Learning ワークスペースの展開用のコネクションを作成します。
- Project Settings > サービスコネクションをクリックします。
- Connection Type には Azure Resource Manager を選択します。
- 認証方式については、デフォルトのサービスプリンシパルにしておきます。今回はスコープレベルはサブスクリプションとしまして、Resource Group はブランクのままで行います。
- サービスコネクションネームについては、先ほど変数のところで設定したazure-rm-csv-connection パラメーターを入れます。
こちらで保存していただくと設定が完了です。


Azure Machine Learningとインフラ環境を構築するためのパイプライン構成
Azure Machine Learning とその周辺サービスのインフラを展開するパイプラインを実装していきます。
Pipelines から新規作成をします。
今回利用する YAML ファイルが保存されているReposGitを選択します。
Pipelines > New Pipelines > Azure Repos Git
複数のタイプからパイプラインを選べますが、
今回は existing Azure Pipeline YAML ファイルを選択します。

こちらはインフラの展開用の YAML ファイルを選択し、Countine をクリックします。> こちらのYAML ファイルが選択されますので、この状態で問題なければ、Run をクリックします。

パイプライン実行完了
パイプラインの実行が完了しますとこちらの画面に遷移します。
ジョブを選択しますと、それぞれの工程の実行履歴がこちらに出力されます。
エラーが起こった場合には、ジョブからエラーコードを確認できます。実際にはこちらのエラーコードを見て対処しつつ、パイプラインの実装を進めていくと言う形になります。

実装確認

実際に展開されたリソースグループを見てみますと、Application Insight、コンテナレジストリ、ストレージ、Azure ML ワークスペースと、
これらを連携するための Key Vault が作成されていることが分かります。
こちらでAzure Pipelinesの設定が完了しました。
1つ目のパイプライン構成 Azure Machine Learning (AML) Model Training CI パイプライン構成
以下のアーキテクチャ図の赤枠部分を構成していきます。

機械学習モデルの作成・及び登録を行うようなパイプライン構成をします。
Azure DevOps コンソールで作業を進める前に、Azure ML のパイプラインを Azure Pipeline から実行できるようにするエクステンションを入れる必要があります。
Azure Machine Learning 拡張機能を Azure DevOps にインストール
このURLからAzure Machine Learning 拡張機能を Azure DevOps にインストールできます。


拡張機能をインストールする DevOps Organizations を選択し、今回はインストール済みとなっていますが、インストールをクリックします。
Azure Machine Learning ワークスペースとの接続
次に、Azure Machine Learning ワークスペースとの接続を構成して行きます
Project Setting > サービスコネクション >
先ほどと同様に Azure Resource マネージャーサービスプリンシパルを選択、設定します。

今度はスコープレベルを Machine Learningワークスペースにします。
そして最初のパイプラインで作成した Resource Group、およびワークスペースを選択し、Services Connection Name には、ライブラリで定義した変数 ws-csv-connection のパラメーターを入れ、セーブをします。
これでコネクションの設定は完了です。

機械学習モデルの CI パイプライン実装
以上の構成で Azure Resource のセットアップやサービス接続の構成が完了しましたので、機械学習モデルの CI パイプラインを実装します。
パイプラインから新規作成をクリック、こちらも先ほどの Azure Machine Learning とその周辺サービスのインフラを展開するパイプライン構築と同じように Azure Repos の対象のリポジトリを選択し、Azure Pipeline YAML ファイルを選択します。
そして CI パイプラインの定義がされている YAML を選択しパイプラインの実行をします。

パイプラインの実行が完了

先ほどの Azure Machine Learning とその周辺サービスのインフラを展開するパイプライン構築と同じように Job からログを確認できます

アーティファクトをクリックしますと、

実際のパイプラインの成果物をこちらで確認することができます。

そしてこの後構築する CD パイプラインにおいて、
今回実行したパイプラインの名称を参照しますので、
こちらで Model-Train-Register-CI に名前を変更しておきます。

Azure Machine Learning ワークスペースに移動で、先ほど作成したパイプラインの結果を確認できます。
2つ目のパイプライン実装 Azure Container Instance (ACI) CD パイプライン構成
Azure Container Instance への CD パイプラインを実装します。

こちらのアーキテクチャ図のこちらの部分を構成していきます
CIパイプラインで作成したアーティファクトを用いて、Azure Container Instance にデプロイするパイプラインを実行します。
パイプライン > 先ほどのパイプライン構築と同じ手順で、Azure Container Instance への CD パイプラインを構築します。

Azure Repos の対象のリポジトリを選択し、
Azure Pipeline YAML ファイルを選択します。
今回は Regression-cd という YAMLファイルを選択します。
こちらでコンティニューを押すと、パイプラインが実行されます。
パイプライン実行完了
パイプラインの実行が完了すると、この画面に遷移します。

AKS の設定がされていない場合には、パイプラインの Deploy to AKS > こちらの工程はスキップされます。なので、現状 ACI のみにデプロイされている状態です。
また、基本的には、最新のモデルをデプロイしますが、特定のバージョンのモデルをデプロイしたいという場合もあるかと思います。

その場合には Deploy to ACIから
Parse json を選択、こちらからモデルのIDを明示することで、
ACI にデプロイされるモデルを変更することが出来ます。
次に、Azure Machine Learning ワークスペースから、AKS 上の推論コンテナを用意します。
AKS 上の推論コンテナを用意
Azure Kubernetes Services (AKS) クラスター構成をします。

こちらのアーキテクチャ図のこちらの部分を構成していきます
Azure Kubernetes Services (AKS) クラスター構成
Azure Kubernetes Services (AKS) クラスター構成をします。
Azure Machine Learning Studioに移動します

コンピューティング > 推論クラスター > 新規作成をクリックします。
コンテナのリージョンを 東日本(Japan East)に設定します。
クラスタで使用するVMのサイズ、こちらはds2で設定します。

コンピューティング名は Azure DevOps で設定した変数名の mlops4-inferenc パラメーターと同じにします。
コンピューティング名を入力したら、作成をクリックします。

3つ目のパイプライン構成 Azure Kubernetes Services (AKS) CD パイプライン構成

アーキテクチャ図のこちらの部分を構成していきます
作成した本番用推論クラスタに CI パイプラインで作成した機械学習モデルをデプロイする Pipeline を実行していきます。

アジュールコンテナインスタンスにモデルをデプロイしたときのパイプラインを再利用します。
こちらで Run New をクリックします。
パイプライン実行完了

処理が完了しますとこのように AKS のデプロイが完了します。
Azure Machine Learning の Data Drift Monitor 機能
最後に Azure Machine Learning の Data Drift Monitor 機能でドリフトを検知できるような仕組みを作成します。

こちらのアーキテクチャ図のこちらの部分を構成していきます
ターゲットのデータセットを監視して、データ誤差の割合が設定されたしきい値を上回る場合にメール アラートを送信するなどの設定が行えます。
ドリフトを検知
推論時点でのデータが学習時点のものと許容範囲を超えて変化することをデータドリフトといい、モデルの推論精度の低下などの影響を及ぼし、機械学習モデルの劣化を引き起こします。

ドリフト検知機能を作成する場合、2種類のデータセットが必要になります。
・モデルの学習に利用したデータセット
・実際の値を含むデータセット が必要です。
・実際の値を含むデータセットには、時系列カラムが必要になります。
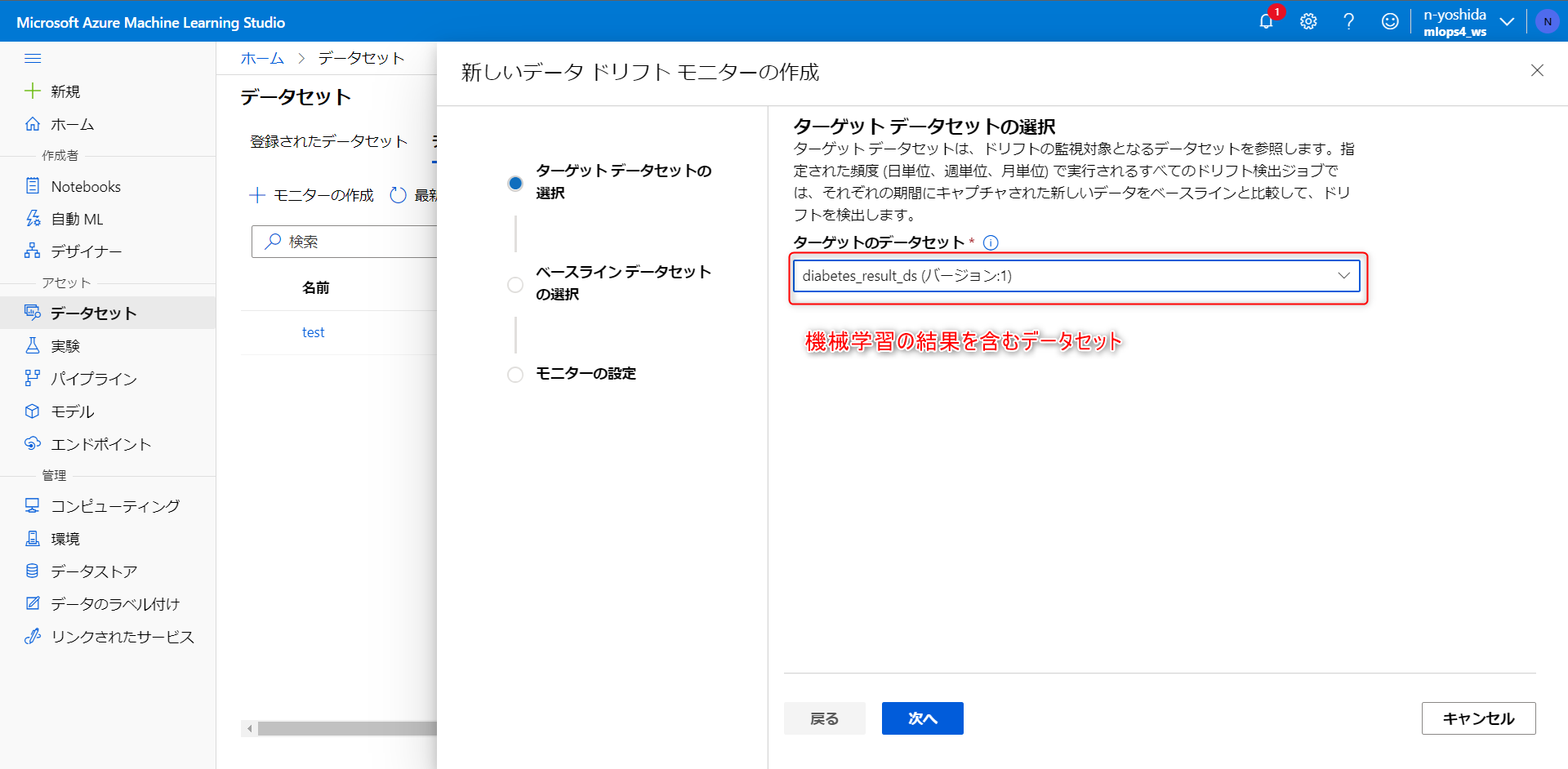
データセットモニター(プレビュー)をクリックし、モニターの作成をします。
まず、機械学習の結果を含むデータセットを選択します。

次に、Baseline Data Set、比較対象のデータセットはモデルの作成に利用したデータセットを選択します。

・モニターの名前を入力
・機能から、モニタリングしたい指標を選択
・コンピューティング先を設定
・データセットに対するモニタリングの頻度、データ誤差の割合のしきい値の設定、
アラートメール通知先の設定が行えます。
こちらで設定が完了です。作成をクリックします。

ドリフトのトラッキングはこのようなダッシュボードで監視可能です。
データサイエンティスト以外のエンジニアもトラッキングしたい場合には、Azure Application Insight と連携するのがいいと思います。
以上で、Azure で MLOps 実装パートを完了します。
最後に
ここまでご覧いただき、ありがとうございました!
機械学習モデルの運用に困ったら、ぜひ MLOps を取り入れてみるといいかなと思います。
Author And Source
この問題について(Azure で ML Ops をやってみる ~実践編~), 我々は、より多くの情報をここで見つけました https://qiita.com/banana-877/items/170123087a9ec4621d69著者帰属:元の著者の情報は、元のURLに含まれています。著作権は原作者に属する。
Content is automatically searched and collected through network algorithms . If there is a violation . Please contact us . We will adjust (correct author information ,or delete content ) as soon as possible .