PythonはウェブページUtf-8の復号エラーとgzip圧縮問題の解決方法を登ります
2505 ワード
python 3でいくつかのサイトを這い出すと、ページurlを取得して解析し、decode('utf-8')復号を採用するとutf-8が復号できないという問題が発生することがあります.例えば、結果はUnicode Decode Error:'utf 8'codec can't decode byte 0 xb 2 in position 0:invalid start byte
これは一部のウェブサイトがgzip圧縮を行ったためで、最も典型的なのはsinaで、ウェブページの爬虫類を行うのはよくこの問題が発生して、それではどうして圧縮しますか?検索犬百科事典は、HTTPプロトコル上のGZIP符号化はWEBアプリケーションの性能を改善するための技術であると説明している.大トラフィックのWEBサイトでは、GZIP圧縮技術を使用して、ユーザーにより速い速度を感じさせることが多い.これは一般的にWWWサーバにインストール機能の1つであり、このサーバのウェブサイトに誰かがアクセスすると、サーバのこの機能はウェブページの内容を圧縮して訪問するコンピュータブラウザに転送する表示される.通常、純テキストの内容は元のサイズの40%に圧縮することができる.これで転送が速くなり、サイトをクリックするとすぐに表示されます.もちろんサーバの負荷も増加します*.*一般的なサーバには、この機能モジュールがインストールされています.ある新浪のページを開き、右クリックして「チェック」を選択し、Network-All」Headersの下の「Request Headers」でこの文字を発見します.Accept-Encoding:gzip,deflate,sdch
この問題には、「設定したヘッダに'Accept-Encoding':'gzip,deflate',という言葉があるかどうかを見て、存在すれば削除すれば解決できます」というアドバイスがあります.しかし、headerにこのコードが存在しない場合があります.どうやって削除しますか?次のように、ある新浪ニュースのページを開く例を示します.
これは一部のウェブサイトがgzip圧縮を行ったためで、最も典型的なのはsinaで、ウェブページの爬虫類を行うのはよくこの問題が発生して、それではどうして圧縮しますか?検索犬百科事典は、HTTPプロトコル上のGZIP符号化はWEBアプリケーションの性能を改善するための技術であると説明している.大トラフィックのWEBサイトでは、GZIP圧縮技術を使用して、ユーザーにより速い速度を感じさせることが多い.これは一般的にWWWサーバにインストール機能の1つであり、このサーバのウェブサイトに誰かがアクセスすると、サーバのこの機能はウェブページの内容を圧縮して訪問するコンピュータブラウザに転送する表示される.通常、純テキストの内容は元のサイズの40%に圧縮することができる.これで転送が速くなり、サイトをクリックするとすぐに表示されます.もちろんサーバの負荷も増加します*.*一般的なサーバには、この機能モジュールがインストールされています.ある新浪のページを開き、右クリックして「チェック」を選択し、Network-All」Headersの下の「Request Headers」でこの文字を発見します.Accept-Encoding:gzip,deflate,sdch
この問題には、「設定したヘッダに'Accept-Encoding':'gzip,deflate',という言葉があるかどうかを見て、存在すれば削除すれば解決できます」というアドバイスがあります.しかし、headerにこのコードが存在しない場合があります.どうやって削除しますか?次のように、ある新浪ニュースのページを開く例を示します.
import BeautifulSoup
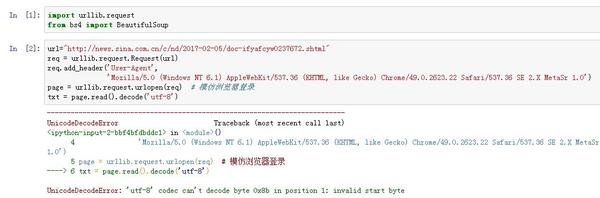
url=’http://news.sina.com.cn/c/nd/2017-02-05/doc-ifyafcyw0237672.shtml’req = urllib.request.Request(url)req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0')
page = urllib.request.urlopen(req) #
txt = page.read().decode('utf-8')
soup = BeautifulSoup(txt, 'lxml')
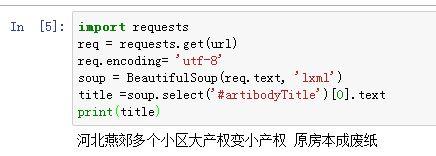
title =soup.select('#artibodyTitle')[0].text
print(title)```
run , *decode('utf-8')* 。 , 。
:(1) gzip ;(2) requests urllib。
(1) : “txt = page.read()” , :
txt=gzip.decompress(txt).decode('utf-8')
(2) :
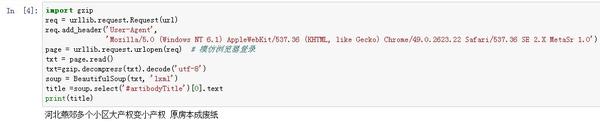
```import requests
import gzip
url="http://news.sina.com.cn/c/nd/2017-02-05/doc-ifyafcyw0237672.shtml"
req = requests.get(url)req.encoding= 'utf-8'```
‘utf-8’ , :
headers = { 'Host': 'blog.csdn.net', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', ….}
, :
*** ***
***Gzip****** ***
***Requests****** ***